

1-3에서의 위치는 데이터의 특징을 요악하는 요소 중 하나.
변이(variability)는 데이터 값이 얼마나 밀집해 있는지 혹은 얼마나 퍼져있는지 산포도(dispersion)를 알려줌.
(기본적 용어 정리가 잘 되어있어서 편하다)
- Deviation: 관측값과 위치 추정값 사이의 차이 (편차, 오차, 잔차)
- Variance: 평균과의 편차를 제곱한 값들의 합을 n-1로 나눈 값. (분산, 평균제곱오차)
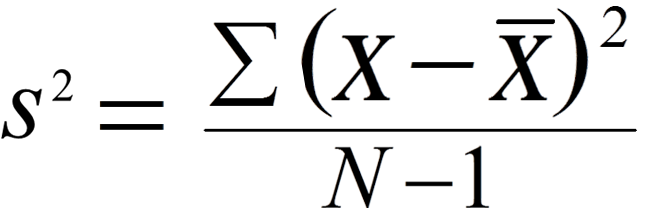
- 뭐 가장 유명한 변이 추정 방법은 당연히 분산이랑 표준편차 쓰는것이다.
- 수학적으로 제곱한 값이 절댓값보다 통계 모델을 다루는 데 더 편리하다는 통계 이론이 이를 뒷받침
- Standard Deviation (STD): 분산의 제곱근
- Mean Absolute Deviation: 평균과의 편차의 절댓값의 평균 (평균절대편차, I1 노름, 맨해튼 노름)

- 편차의 평균은을 구하는건 좋게 보지 않는다고 한다, 왜냐하면 음의 편차는 양의 편차를 상쇄시켜버리기 때문.
- 그것을 보완하기 위해서 절댓값의 평균을 구하는 것이다.
- Median Absolute Deviation from the Median(MAD): 중간값과의 편차의 절댓값의 중간값

- 분산, 표준편차, 평균절대편차 이런건 모두 극단값에 로버스트하지 않다. (즉, 민감하다)
- 로버스트한 변이 추정값이 MAD이다.
- Range: 데이터의 최댓값과 최솟값의 차이
- 범위는 그 순서 통계량에서의 min ~ max의 차이
- Order Statistics: 최소에서 최대까지 정렬된 데이터 값에 따른 계량형 (순위,,)
- 변이를 추정하는 또 다른 접근은 정렬된 데이터가 얼마나 퍼져 있는지 확인 하는 것
- 쉽게말해서 sorting(정렬) 데이터를 나타내는 통계량을 순서 통계량이라 부름
- Percentile: 크기가 있는 값들로 이뤄진 자료를 순서대로 나열할때, 백분율로 나타낸 특정 위치의 값을 나타내는 용어
- 특잇값에 민감한 것을 피하기 위해서, 양 끝 값들을 지우고, 범위를 다시 알아보는, 백분위수 사이의 차를 가지고 추정 하는 방법도 있음

- Interquartile Range (IQR): 75번째 백분위수와 25번째 백분위수 사이의 차이
자유도에 대한 내용이 잠시 나오는데, 그건 좀 더 디테일하게 예제나 나오면 그때 정리하겠음.
예제: 주별 인구의 변이 추정
#STD
state['Population'].std()
#IQR
state['Population'].quantile(0.75) - state['Population'].quantile(0.25)
#MAD
robust.scale.mad(state['Population'])
pandas에서 쉽게 std, iqr을 구할 수 있고, MAD를 위해서는 statsmodels 패키치의 strong.scale.mad를 사용.
'Machine Learning > Practical Statistics' 카테고리의 다른 글
| [Practical Statistics] 이진 데이터와 범주 데이터 탐색 (0) | 2022.03.12 |
|---|---|
| [Practical Statistics] 데이터 분포 탐색하기 (0) | 2022.03.04 |
| [Practical Statistics] 위치 추정 (0) | 2022.03.01 |
| [Practical Statistics] 테이블 데이터 (0) | 2022.02.27 |
| [Practical Statistics] 탐색적 데이터 분석 (EDA) (0) | 2022.02.25 |