
지난번에는 상관관계를 통해서 두개의 변수에 상관관계를 보았는데, 이번엔 두 개 이상이다.
평균과 분산처럼 익숙한 추정값들을 통해 한번에 한의 변수를 다루는 건 일변량분석(univariate analysis)이라고도 부른다.
상관분석처럼 두개의 변수에서 비교할때는 이변량분석(bivariate analysis)이라고 불리며,
이번에는 추정값과 도표, 그리고 셋 이상의 변수를 다루는 법, 즉 다변량 분석(multivariate analysis)에 초점을 둔다.
추가로 일변량 분석과 마찬가지로, 이변량 분서에서도 요약통계를 계산하고 시각화를 기본으로 한다.
그리고 이변량 또는 다변량 분석에서의 형태는 데이터가 수치형인지 범주형인지, 데이터 특성에 따라 달라진다.
육각형 구간과 등고선 (Hexagonal Bining and Contours)
사실 모바일 광고 트래픽을 열심히 분석하는 입장으로서 산점도는 그렇게 좋지 않다.
데이터의 양이 상당히 많고, 그냥 보이는 트래픽이 몇십억에 로그로 들어가게되면 정신이 혼미해진다.
이 책에서 다시 한번 또 배우는 느낌인데, 상당히 많은 레코드를 산점도를 나타내는 것 보다는 다른 방식이 필요로 하다.
제공해준 데이터를 통해서 공부해보쟈.
해당 테이블은 워싱턴 주의 한 지역에 대한 주택 시설에 대해 과세 평가금액 정보를 담고있다.
행을 조회해보니 약 50만개의 데이터가 있는데, 데이터 주요 부분에 집중하기 위해서 필터링을 해준다.
(아직은 이상치를 제거한다기 보다 주요부분을 그냥 짤라서 보는 느낌)
# 데이터 주요 부분 짜르기
kc_tax0 = kc_tax.loc[(kc_tax.TaxAssessedValue < 750000)&
(kc_tax.SqFtTotLiving >100)&
(kc_tax.SqFtTotLiving<3500),:]
len(kc_tax0)일단 50만개에서 43만개정도로 감소했다.
그리고 바로 육각형 구간을 통해서 어떤 관계를 가지고 있는지 확인해보면...
#육각형 구간을 그려봅시다.
ax = kc_tax0.plot.hexbin(x='SqFtTotLiving', y='TaxAssessedValue',
gridsize=30, sharex=False, figsize=(12, 8), cmap ='Oranges')
#라벨링만 해주고
ax.set_xlabel('Finished Square Feet')
ax.set_ylabel('Tax Assessed Value')
#그래프 그리기
plt.tight_layout()
plt.show()
책에서는 육각형 구간을 통해서 점으로 표시하는 대신 기록값을 육각형 모양의 구간들로 나누고 구간에 포함된 기록값 갯수에 따라 색을 표시 할수 있다고 설명한다.
궁금해서 조금 더 찾아보았다.
https://datavizproject.com/data-type/hexagonal-binning/
Hexagonal Binning | Data Viz Project
Hexagonal Binning is another way to manage the problem of having to many points that start to overlap. Hexagonal binning plots density, rather than points. Points are binned into gridded hexagons and distribution (the number of points per hexagon) is displ
datavizproject.com
해당 사이트에서는 산점도와 다르게 밀도까지 함께 표시를 해준다고 명시하면서 책에서와 같이 너무 많은 양의 포인트를 쉽게 관리할 때 사용한다고 한다.
(1987년에 나왔다는데, 참 대단한 사람들이다...)
암튼 육각형 구간으로 간단히 분포와 밀도를 확인했다면, 등고선을 활용해서 변수 사이의 관계를 시각화 해보자.
위의 결과와 비슷하게 나와야한다.
#사이즈만 먼저 지정해주고요
fig, ax = plt.subplots(figsize=(12, 8))
sns.kdeplot(data=kc_tax0.sample(50000), x='SqFtTotLiving', y='TaxAssessedValue', ax=ax, cmap='Oranges')
ax.set_xlabel('Finished Square Feet')
ax.set_ylabel('Tax Assessed Value')
plt.tight_layout()
plt.show()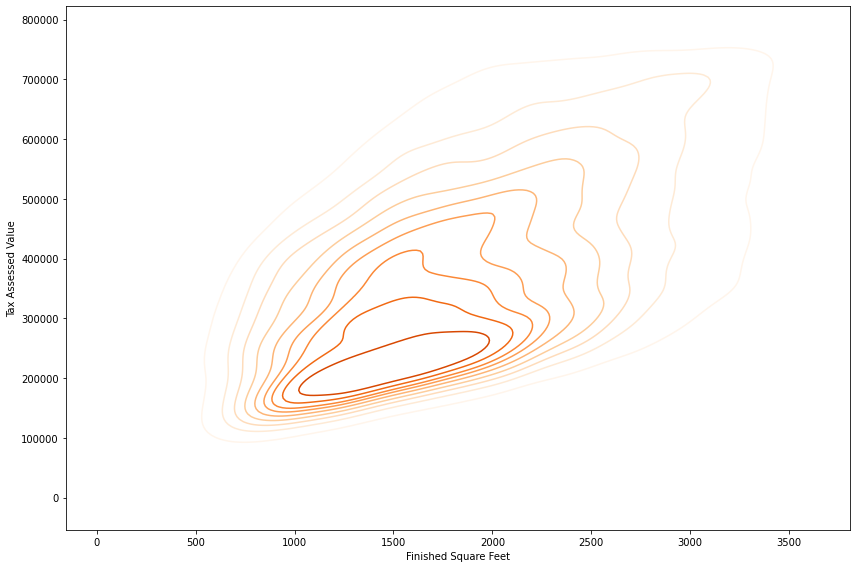
뭣 모르고 한참 기다릴뻔 했다.
위의 육각형 구간과 다르게, 로드 시간이 상당히 걸렸는데 그래서 스탑시켜버리고 sample만 가지고 와서 그렸다.
암튼 등고선 위의 점들은 밀도가 같으면서, 높은 지점으로 갈수록 밀도가 높아진다고 생각하면 된다.
추가로 예전에 회사에서 썼던 시각화자료가 생각나서 추가하자면, 육각형 구간 또는 등고선 그래프와 옆에 분포까지 쉽게 볼수있도록 하는 시각화 자료도 있다. seaborn에서 jointplot을 사용했다.
#jointplot으로 육각형 구간과 히스토그램으로 분포같이 그리기
with sns.axes_style('white'):
sns.jointplot('SqFtTotLiving', 'TaxAssessedValue', kc_tax0, kind='hex')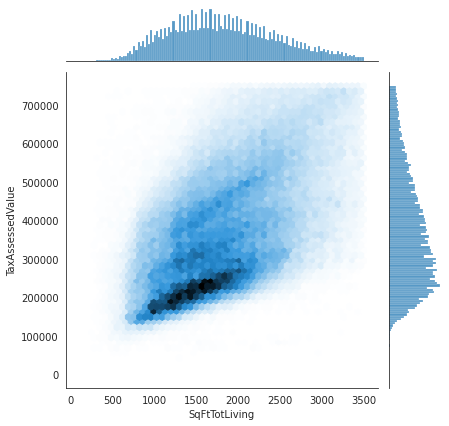
#jointplot으로 등고선과 추가로 밀도를 볼수있는 곡선그래프
with sns.axes_style('white'):
sns.jointplot("SqFtTotLiving", "TaxAssessedValue", kc_tax0, kind='kde');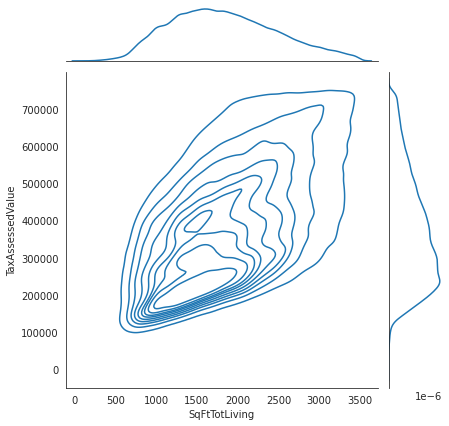
범주형 변수 대 범주형 변수 (Two Categorical Variables)
분할표의 목적 자체가 두 범주형 변수의 빈도수를 기록하는 표이면서 상당히 효과적이고, 사실 이거 말곤 잘 모르겠다..
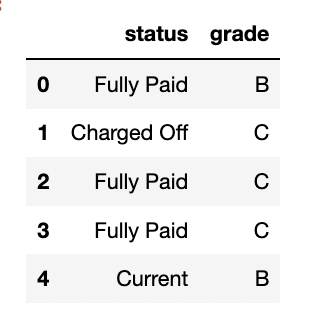
역시 제공해준 데이터를 활용해보자.
대출에서의 등급을 나타네는 건데, 어떻게 정리할지 한번 보자. 다른 수치가 아니라 단지 status와 grade뿐이다.
# pivot table을 활용
crosstab = lc_loans.pivot_table(index='grade', columns='status',
aggfunc=lambda x: len(x), margins=True)
print(crosstab)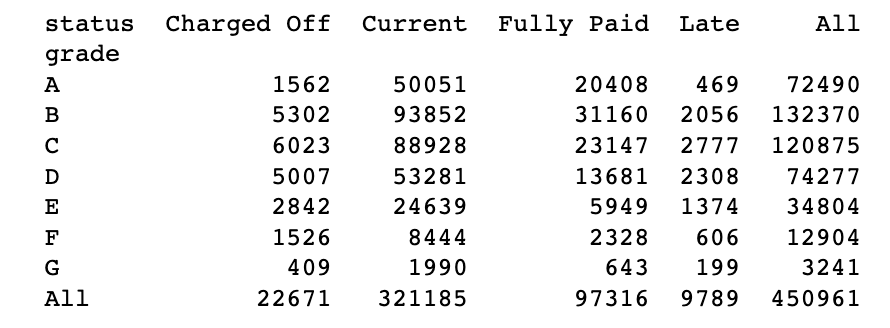
간단하게 피벗 테이블을 사용해서 status 와 grade를 잘 분류해서 그에 속하는 수를 잘 가지고 왔다.
근데 R을 활용하면 바로 비율까지 나오는 것같은데, 파이썬의 경우 추가적으로 코드가 필요하다.
#하나 카피 떠두고
df = crosstab.copy().loc['A':'G',:] #근데 열의 합계는 무시해버린다.
#행 합계로 행을 나눈다고 써있는데, 굳이 이렇게?..
df.loc[:,'Charged Off':'Late'] = df.loc[:,'Charged Off':'Late'].div(df['All'], axis=0)
#비율로 보기위해 'All'열을 'All'열의 총합으로 나누기
df['All'] = df['All'] / sum(df['All'])
perc_crosstab = df
print(perc_crosstab)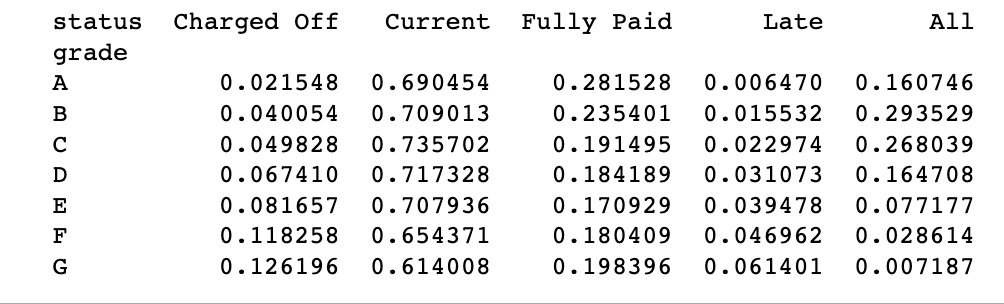
상당히 귀찮지만, 백분율까지 보고싶다고하니 다시 정리해줬다.
범주형 변수 대 수치형 변수 (Categorical and Numeric Data)
보통 이럴때 boxplot을 사용한다.
box plot을 사용하여 범주형 변수에 따라 분류된 수치형 변수의 분포를 시각화 하는 것.
(상자그림이라고 써있는데 익숙하지 않다. 어감이..)
이번 데이터 예제는 항공사별 지연 비율을 보기위해 위의 데이터를 가지고 왔다.
#간단히 boxplot 그리기
ax = airline_stats.boxplot(by='airline', column='pct_carrier_delay',figsize=(12, 8))
ax.set_xlabel('airline')
ax.set_ylabel('Daily % of Delayed Flights')
plt.suptitle('')
plt.tight_layout()
plt.show()
보기 깔끔하다. 데이터가 잘 정제가 된거라 그른가..
암튼 살짝 보면 알래스카 항공이 지연이 다른 항공사에 비해 적었고, American airline이 가장 많았다. 이상치는 보지 않고 박스 안에서만 비교한다면.
(근데 실제로 경험으로 이야기 하자면, American 항공은 지연이 진짜 많다... 추가로 United도!)
boxplot말고 violin plot도 하나의 방법인데 , 밀도를 좌우 대칭으로 보기 쉽게 만들어주기 때문에 boxplot에서 놓칠 수 있는 부분을 커버한다.
정리하자면 boxplot은 이상치를 잘 보여주고, violinplot은 밀도를 잘 표현하니 두개 잘 적절히 사용하면 좋겠다.
#violinplot
fig, ax = plt.subplots(figsize=(12, 8))
sns.violinplot(data=airline_stats, x='airline', y='pct_carrier_delay', ax=ax, inner='quartile', color='white')
ax.set_xlabel('')
ax.set_ylabel('Daily % of Delayed Flights')
plt.tight_layout()
plt.show()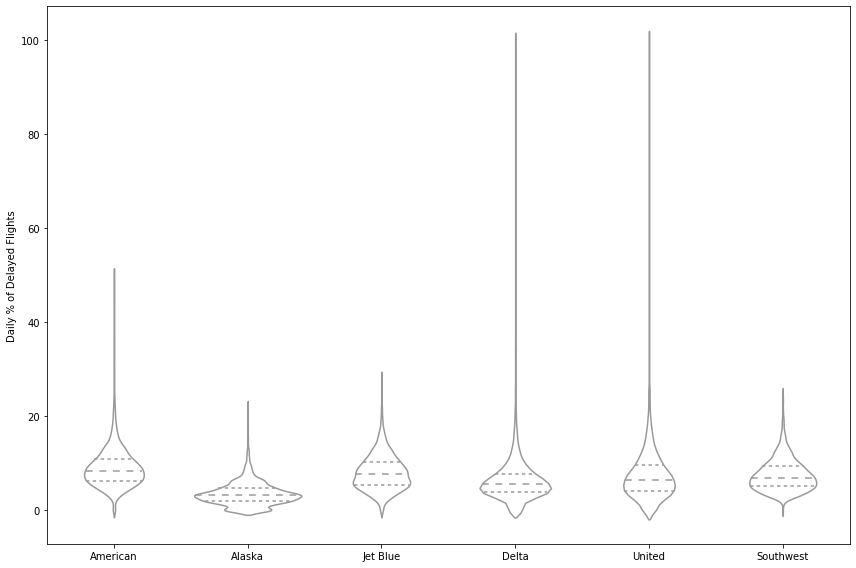
(두개 다 pyplot으로도 더 깔끔하게 그릴 수 있지만, 담기회에.. )
다변수 시각화하기 (Visualizing Multiple Variable)
마지막으로 다양한 변수를 함께 시각화하여 보는것이다.
예를들어 아까 사용한 그 워싱턴 주의 한 지역에 대한 주택 시설에 대해 과세 평가금액 정보에서 zipcode가 다를때마다 평가액이 다를 수 있기 때문에 zipcode별로 한번 그룹을 지어주고 도식화를 시ㅕㅋ보자.
이러면 서로 다른 그룹들을 한번에 설명 가능하게 해준다.
#보고싶은 4개의 zipcode를 설정해주고
zip_codes = [98188, 98105, 98108, 98126]
#처음 가지고 왔던 테이블에서 따로 zipcode 정보만 모은걸 만들어준다.
kc_tax_zip = kc_tax0.loc[kc_tax0.ZipCode.isin(zip_codes),:]
kc_tax_zip
#함수 하나 지정해준다면 hexbin 육각형 구간 다시 가지고 와주고,
def hexbin(x, y, color, **kwargs): ## kwargs는 keyword argument의 줄임말. 특정값 형태로 함수 호출
cmap = sns.light_palette(color, as_cmap=True)
plt.hexbin(x, y, gridsize=25, cmap=cmap, **kwargs)
#FaceGrid를 사용하여 그래프를 여러개 보여주는 것
g = sns.FacetGrid(kc_tax_zip, col='ZipCode', col_wrap=2)
g.map(hexbin, 'SqFtTotLiving', 'TaxAssessedValue', extent=[0, 3500, 0, 700000]) #조건을 여기서도 바로 걸어줄 수 있음
g.set_axis_labels('Finished Square Feet', 'Tax Assessed Value')
g.set_titles('Zip code {col_name:.0f}')
plt.tight_layout()
plt.show()
보면 네가지의 다른 zip code별 다른 형태의 그래프를 보여준다는걸 쉽게 확인 할 수 있다.
이렇게 책에서 설명하는 챕터 1. 탐색적 데이터 분석 (EDA)파트가 마무리가 되었다.
가장 기본이면서 우선적이고 중요한 과정이다.
데이터를 요약하고 시각화하는 것을 통해 데이터에대한 인사이트를 발견하는 단계라고 보면 좋을것같다.
'Machine Learning > Practical Statistics' 카테고리의 다른 글
| [Practical Statistics] 선택 편향 (0) | 2022.03.24 |
|---|---|
| [Practical Statistics] 데이터와 표본분포 (0) | 2022.03.20 |
| [Practical Statistics] 상관관계 (0) | 2022.03.14 |
| [Practical Statistics] 이진 데이터와 범주 데이터 탐색 (0) | 2022.03.12 |
| [Practical Statistics] 데이터 분포 탐색하기 (0) | 2022.03.04 |