
요즘 집중력도 별로 떨어지고, 의욕도 많이 안생겨, 스트레스는 너무많아서 집에서 하기는 싫고, 카페를 가는것도 요즘 귀찮아지고 해서!!
스터디 카페를 좀 알아보고있다.
한번씩 근처에 있는곳 가보고 정해봐야지.
(막상 가서 할거는 블로그, 데이터 관련 공부하고, 주식 코드짜기, 주식 관련 아티클 보고, 책일고,,,
열공하고 막 자격증 따는것도 아닌데 가도 되는건가...)
혼공파랑은 조금 다르게 스토리?로 시작을 하는데,
앱 마켓에서 최초로 살아있는 생선을 파는 이야기로 시작한다.
간단히 목적만 요약을 해보자면, 회사에서의 목적은 살아있는 생선의 이름을 자동으로 알려주는 머신러닝을 만들라는 지시를 받고 업무를 진행하는 내용이다.
간단한 예제도 있겠다, 오픈 소스도 있겠다, 바로 코드 파고 들어가봅시다.
https://www.kaggle.com/datasets/aungpyaeap/fish-market
Fish market
Database of common fish species for fish market
www.kaggle.com
생선 분류 문제
책을 따라가기전에, 데이터 셋을 먼저 받았으니 간단히 그냥 데이터프레임 확인만 해보자.
#어느정돈지 파악해보고
df.head()
#종류는 얼마나 있는지 확인도 해보자
df['Species'].unique()

뭐 무게와 길이 그리고 높이와 넓이 정도의 수치형과 종류가 있고,
종류는 7종류의 물고기가 있다.
책에서 나오는 김팀장님은, 생선 길이가 30cm이 넘으면 도미라고 알려줬다고 한다.
(논리가 없지만,,,)
그래서 혼공머신(책에서 나오는 주인공?)은 바로 아래처럼 코드를 짰다.
#책에서는 fish_length로 나와있음
if Length1 >=30:
print("도미")하지만 진짜 논리가 없는 의견이니 당연히 문제가 많을 수 밖에 없다.
무조건 30만 넘으면 도미라고 말할 수 없지 않겠는가..
그렇다면 어떻게 정의를 해야 머신러닝으로 문제를 해결할 수 있을까?
잠시만,
머신러닝이라는 것은 사람(누군가)가 알려주지 않은 일을 기계가 스스로 학습하는 것이다.
즉, 내가 무언가 정의하지 않고 스스로 도미를 찾을 수 있어야한다.
도미 데이터 준비하기
그러면 머신러닝에게 도미 생선을 많이 보여준다면, 스스로 찾을 수 있을 것이다.
이유는 아직 모르겠지만, 책에서 새로운 노트를 열고 데이터를 넣어주기로 했다.
(책에서는 코랩을 사용하지만, 나는 jupyterlab을 통해 항상 작업하기에 jupyterlab을 활용하는중이다.)

#도미 35마리 데이터 넣어주기
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]리스트 형식이기 때문에,
첫번째 도미의 길이는 25.4이면서 무게는 242이고, 쭉쭉쭉 한마리씩의 특징이라고 보면 된다.
이것이 하나의 도미의 특징이며, 이런 특징들을 Feature라고도 부른다.
사실 저렇게 보니까 너무 뭔가 보기 힘든데, 그럴때는 바로 뭐? 시각화 시켜서 한눈에 편하게 보면 된다.
이차원이니까 x를 length로 잡고 y를 weight으로 잡고 편하게 산점도를 확인해보자
- 산점도: x, y축으로 이루어진 좌표계에 두 변수(x, y)의 관계를 표현하는 방식
어떤 라이브러리를 사용해도 상관 없지만, 책에서는 matplotlib을 사용했다.
import matplotlib.pyplot as plt
plt.scatter(bream_length, bream_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
누가봐도 매우 선형적인 그래프가 똿 나왔다.
조금 더 생각해보면, 당연히 생선이니까 길이거 길어질 수록 무게도 당연히 많이 나간다고 생각하면 뭐 자연스러운 데이터이다.
도미는 되었고, 그럼 빙어?데이터를 또 가지고 와서 똑같이 산점도를 그려볼텐데!
한 테이블에 두개의 데이터를 넣어보자. 비교를 하기위해서
#빙어 14마리 데이터
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
#도미
plt.scatter(bream_length, bream_weight)
#빙어
plt.scatter(smelt_length, smelt_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
그치, 빙어는 일단 쪼끄마한 친구니까 데이터가 저렇게 나뉘어 보인다
빙어는 뭐 길이가 늘어난다고해도 무게에 크게 영향을 주지는 않는다.
그러면 이제 도미와 빙어를 구분하는 머신러닝 프로그램을 간단히 만들어봅시다.
첫 번째 머신러닝 프로그램
첫번째로 나오는 알고리즘은 k-최근접 이웃 (k-Nearest Neighbors) 알고리즘이다.
(자세한 알고리즘에 대한설명도 없이 넘어가나 해서 책 뒤까지 살펴보았는데, 다행이도! 간단히 개념 설명이 있으니 그때가서 다시 설명하겠다.)
일단 작업을 하려면 두 리스트를 하나의 리스트로 합쳐주어야 한다.
그리고 나서 책에 나온 것 처럼 scikit-learn을 사용해줘야하기 때문에 리스트 형식을 세로로 펼쳐주는?작업이 필요하다.
즉, 2차원의 리스트 형식으로 바꾸어줘야한다.
(사이킷런은 머신러닝 패키지고, 2차원 리스트를 필요로 하니 참고하자)
#리스트를 하나로 만들어주고
length = bream_length + smelt_length
weight = bream_weight + smelt_weight
#사이킷런을 사용하기 위해 리스트를 세로방향으로 늘어뜨린 2차원 리스트를 생성해야함
#zip함수 = 나열된 리스트 가각에서 하나씩 원소를 꺼내 반환하는 것
fish_data = [[l, w] for l, w in zip(length, weight)](나도 for문을 이렇게 쓰라고 하면 바로 익숙하게 사용하기는 좀 어려움이 있지만,, 계속 보다보면 뭐 도움이 될것이당)
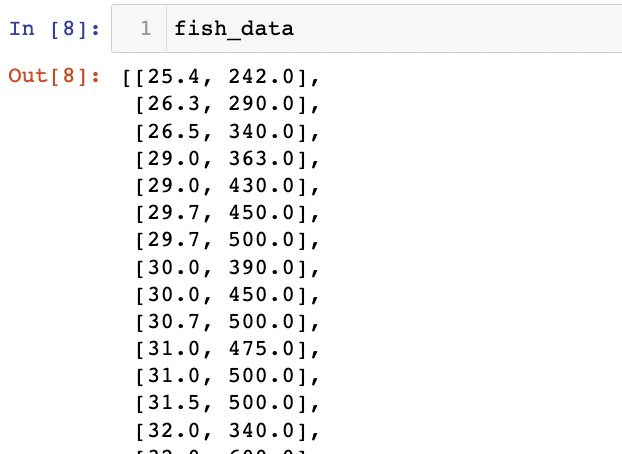
이런식의 fish_data가 생성이 되고 2차원 리스트를 완성했다.
생선 49개의 길이와 무게가 모두 정리된 테이터가 되었는데, 이제는 정답데이터가 필요로 하다.
쉽게 말해서 도미와 빙어를 숫자 1, 0 으로 표현을 해야 컴퓨터는 규칙을 찾기 원하고 규칙마다 정답을 알려주어야한다.
아까 리스트를 처음에 생성할때 첫 35마리는 모두 도미, 그리고 나머지는 빙어였다.
그러면 곱셈 연산자를 통해서 정답을 알려줘보자.
fish_target=[1]*35 + [0]*14
print(fish_target)
이런식으로 정답에 대해서 1, 0으로 놓는 형식은 머신러닝에서 계속 쓰이게 된다.
대부분 정답?혹은 구하려는 대상을 1로 놓고 그 외는 0으로 놓는게 일반적이다.
자, 정답 셋도 준비가 되었으니 사이킷런 가지고옵시다.
k-최근접 이웃 알고리즘 (이하k-nn)을 구현하기 위해 KNeighborsClassifier를 임포트해주면 된다.
그리고 나서 클래스 객체를 만든다
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()자, 이 객체에 fish_data와 fish_target을 전달해서 기준을 학습시킬 것인데, 그 과정을 우리는 training (훈련)이라고 부르고, 사이킷런에서는 fit() 메서드가 이런 역할을 한다고 한다.
fit() 메서드는 주어진 데이터로 알고리즘을 훈련한다고 한다.
그리고 얼마나 잘 훈련이 되었는지 평가를 할 수 있는데 평가할때의 메서드는 score()메서드를 사용해주면 된다.
값은 항상 0~1사이로 반환하는데 1이 모든 데이터를 다 맞췄다는 뜻이다.
kn.fit(fish_data, fish_target)
kn.score(fish_data, fish_target)먼가 1.0짜리 score를 반환시켜주었는데,, (의심 한가득이다)
아무튼 이런 값을 또 score값이 아닌 정확도라고 생각하면 좀 편할것이다.
그럼 예를 들어서 뭐 길이는 30에 무게가 600이라는 데이터를 넣고 판단하면 어떤것으로 예측을 할까?
#predict를통해서 예측하기 원하는 데이터 값을 넣어주면 1과 0 중에서 알고리즘을 통한 값을 반환시켜준다
kn.predict([[30,600]])
확실히 도미의 데이터들이 높은 값을 가지고 있으며, 근처에 많으니 1을 반환시켜주었다.
(여러 문제점이 많이 보이지만, 책에서 그 과정을 하나하나 차근차근 잡고 가는 것같아서 좋다)
아무튼 k-nn을 사용할때에 준비해야할 것은 데이터를 모두 가지고 있어야하고, 예측할때 가장 가까운 직선 거리에 어떤 데이터가 있는지 살피면 된다.
단점은 아주 많은 데이터를 사용하기에는 부정확하고, 계산량이 많이 들어간다고 한다.
(리스트 형태로 엄청 많은 데이터를 넣고 한다면 좀 계산하는데 부담이 많이 되나보다)
자, 내가 궁금한 이야기를 하나 해주는데,
k-nn은 k-mean에서 나온 개념이고 그러면 예측할 때 직선거리가 가까운 데이터 몇 개를 참고해서 결정하나?
KNeighborsClassifier에서는 기본적으로 5개로 설정이 되어있다고 한다.
그리고 우리는 n_neighbors로 언제든 매개변수를 변경 해 줄 수 있다.
Summary
간단히 두 종류의 생선을 분류하는 과정이였고,
도미, 빙어의 데이터를 합쳐서 하나의 리스트 데이터를 준비했다.
그리고 나서 k-nn알고리즘을 사용했고 주변의 5개의 데이터를 보고 다수결?원칙에 따라 데이터를 예측하였고 정확하게? 예측을 하였다.
배운점은,
KNeighborsClassifier 클래스의 fit(), score(), predict() 메서드를 사용하였음
마지막에 요약해주는 것도 내 스타일이고, 괜찮은 책이다.
개념설명이 너무나 부족한건 있찌만,, 그래도 괜찮아!
'Machine Learning > ML - 혼공머신' 카테고리의 다른 글
| [혼공머신] K-최근접 이웃 회귀 (2) | 2022.11.02 |
|---|---|
| [혼공머신] 데이터 전처리 (1) | 2022.10.15 |
| [혼공머신] 훈련 세트와 테스트 세트 (2) | 2022.09.14 |
| [혼공머신]인공지능과 머신러닝, 딥러닝 (0) | 2022.05.28 |