
상관관계
상당히 자주 그리고 많이 사용했었던 상관관계다.
업무 특성상 과연 이게 상관관계가 있는건가?라는 의문을 던지고 확인 하는 일이 많다.
다양한 방법이 있지만, 데이터에서 상관관계를 먼저 파악하게 되면 후에 분석에서 용이하기 때문에 엑셀이든 파이썬을 사용하든 상관관계 먼저 파악하고 업무를 시작했었다.
상관관계를 더 쉽게 말하면, x라는 값이 커지면 y값도 같이 증가하는지 (양의 상관관계), 반대로 x는 상승하지만 y는 감소할때, (음의 상관관계) 이런거를 파악하는데 아래 좀더 자세히 하나씩 파보자.

위에서 잠시 말한 양의 상관관계, 음의 상관관계를 잘 보여준 이미지다.
- Positive Correlation: x축이 증가할때 y축의 값도 함께 증가하는 추세
- Negative Correlation: x축으로 데이터가 증가하지만, y축은 감소하는 추세
- Zero Correlation: 뜻깊은 의미를 찾기 힘든 데이터 분포를 나타낼 때
이걸 그럼 매일 그래프 그리고 눈으로 파악해야하냐? 절대 아니다.
쉽게 상관계수를 통해서 데이터를 꼭 시각화하지 않더라도 상관관계를 파악할 수 있다.

| xi | values of the x-variable in a sample |
| x bar | mean of the values of the x-variable |
| yi | values of the y-variable in a sample |
| y bar | mean of the values of the y-variable |
복잡해보이지만 생각보다 간단한 공식이다.
두 변수 사이의 상관관계를 같은 척도에 놓고 추정하는 방식이라고 보면 편한데, 각 변수의 평균으로부터 편차들을 서로 곱하고, 그 값들의 평균을 각 변수의 표준편차의 곱으로 나눠주는것이다.
범위는 -1 부터 +1까지이고, 수치적 변수들 간에 어떤 관계가 있는지 사용하는 측정량으로 손쉽게 양의 상관관계인지, 음의 상관관계인지 알 수있다. (+1에 가까울 수록 positive, -1에 가까울수록 negative)
(학부때 손으로 열심히 풀었던 기억이 있는데, 파이썬이나 코드 몇줄이면 구하는게 참...늙었다는게 아니고 손으로 풀때는 공식 하나하나 뜻하는 바가 무엇인지 고민하면서 했다면, 코드로 구할때는 빠르게 값을 도출하는게 목적이니.. 암튼 뭐 그냥 그렇다고)
예제 코드를 그래도 봐야겠지?
상관관계-코드예제
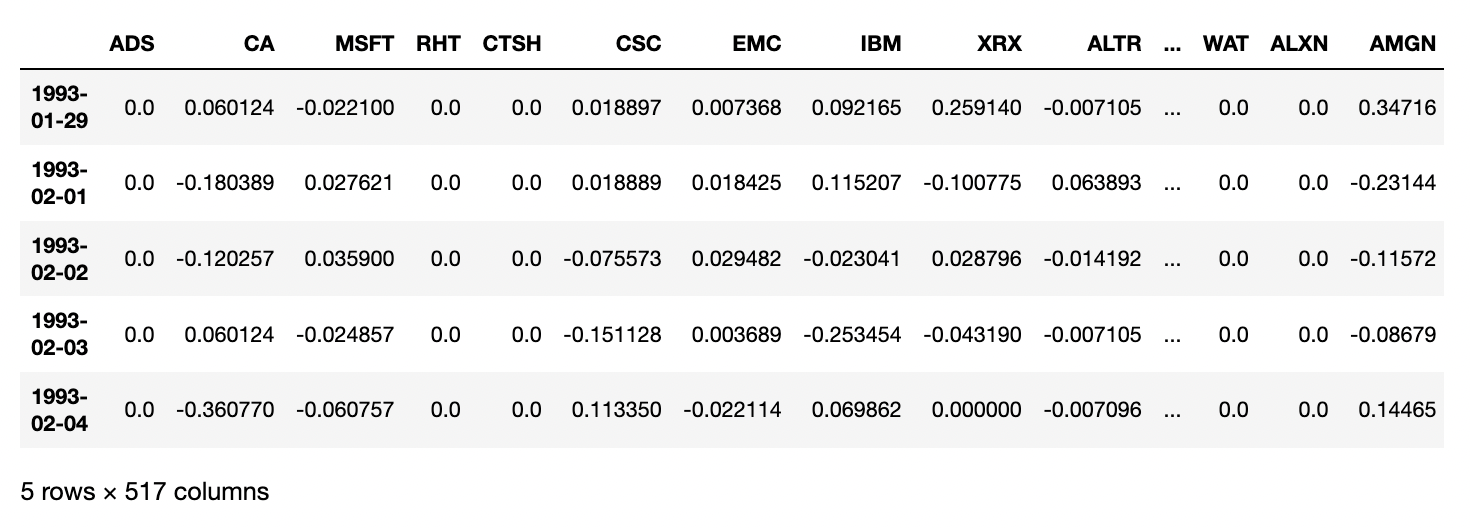

책에서 제공해주는 github에들어가서 데이터를 일단 불러온다.
주식 종목에 대한 기본적인 수익률과 색터별 정리된 테이블.
종목을 조인 시켜줘야겠다. -> 아주감사하게도 낼 주식 트레이딩봇 관련해서 작업하는거랑 겹친다!!
#두 테이블에서 공통적으로 가지고있는 컬럼, symbol을 조인?시켜주고
telecomSymbols = sp500_sym[sp500_sym['sector'] == 'telecommunications_services']['symbol']
# 책에 나오는데로 12년부터 15년 데이터만 조회하고 바로 상관관계를 가지고 와보자
telecom = sp500_px.loc[sp500_px.index >= '2012-07-01', telecomSymbols]
telecom.corr() #바로 상관계수를 구하기
print(telecom)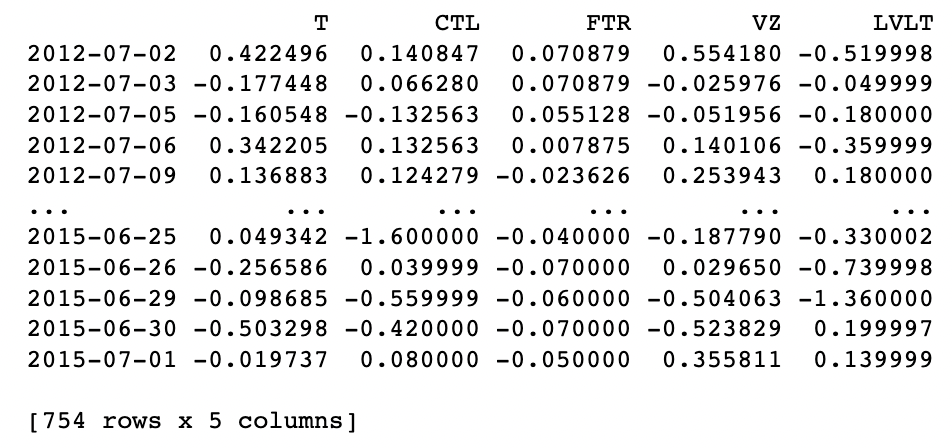
그리고 바로 상관계수를 보게되면 -1 ~ +1까지 각 종목별 상관계수를 너무나 간단히 바로 구해준다.
#etf들도 역시 색터로 조인 시켜주고
etfs = sp500_px.loc[sp500_px.index > '2012-07-01',
sp500_sym[sp500_sym['sector'] == 'etf']['symbol']]
print(etfs.head())
책에서 한느것 처럼 ETF는 S&P500이랑 (SPY)랑 다우지수(DIA)랑도 관련이 높게 나온다.
(여기서 이렇게 주식데이터 활용을 같이 해볼수있어서 너무나 반갑고 좋다.. 역시 데이터 넘치는 주식시장, 이래서 더 맘에 든다)
암튼 그리고 좀더 데이터를 디테일하게 보면, QQQ(미국주요it회사 모음), ILK과도 양의 상관관계를 보여준다.
미국 주식 관련해서도 기회가 되면 하나씩 정리해보면 좋겠다. 사실 미국장은 ETF투자만으로도 충분히 수익률을 올릴 수 있다고 생각하기 때문에.
#상관관계를 보기위해 간단한 시각화를 시켜본다, heatmap으로
fig, ax = plt.subplots(figsize=(5, 4))
ax = sns.heatmap(etfs.corr(), vmin=-1, vmax=1,
cmap=sns.diverging_palette(20, 220, as_cmap=True),
ax=ax)
plt.tight_layout()
plt.show()
위의 상관관계를 보여주는 시각화 자료는 책에서 제공한 코드를 사용하는거고, 옆에 더 새련된 테이블이 있지만, 내가 주로 사용하는 상관관계 시각화 코드를 붙혀보겠다.
(사실 내가 다 짰다 라고 하기 보단 너무나 공용화 된 상관관계 시각화 코드라 어디서든 비슷한게 보일 수 있다.)
#히트맵도 잘 보이지만, 책에 나온 방식이 아닌 다양한 방식으로 상관관계 지표 구해줄 수 있다.
etfs = etfs.corr()
fig, ax = plt.subplots( figsize=(14,14) )
# 삼각형으로 짤라서 보면 편함
mask = np.zeros_like(etfs, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
# 히트맵을 그린다
sns.heatmap(etfs,
cmap = 'RdYlBu_r',
annot = True, # 실제 값을 표시한다, 실제 숫자값이 나와야 난 보기가 좋았음
mask=mask,
linewidths=.5, # 경계면 실선
cbar_kws={"shrink": .5},
vmin = -1,vmax = 1
)
plt.show()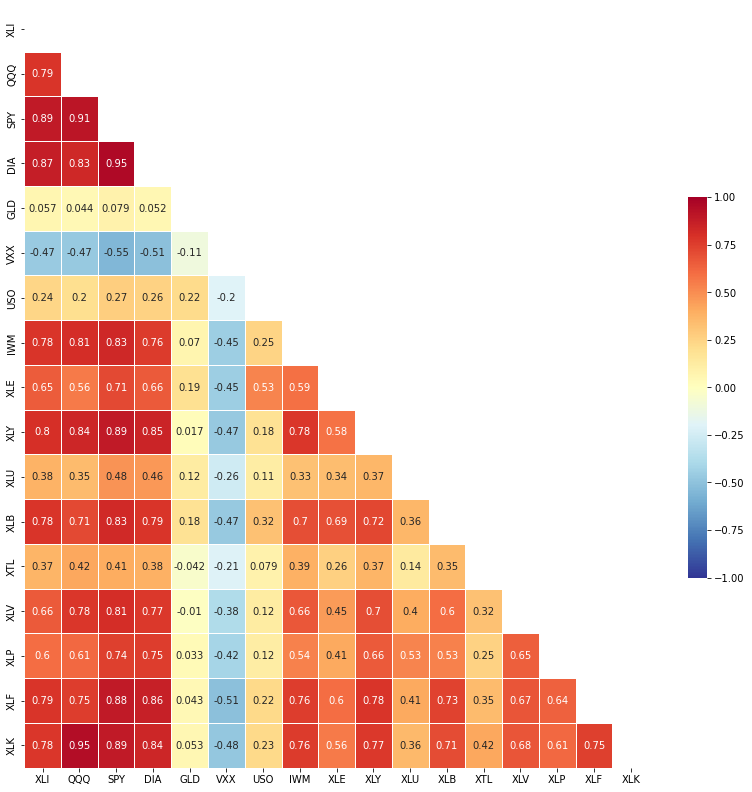
시각화 자료를 보고 판단하는건 데이터를 보고 활용하는 사람들의 몫이니까, 그리고 제 3자도 잘 이해하기만 한다면 어떠한 시각화 자료를 활용해도 상관 없다고 본다.
기왕 다른 코드 쓰는거 산점도도 다르게 뿌려보자.
산점도
사실 변수가 두개라면, 산점도를 통해서 바로 상관관계를 보면 좋다.
좌표평면에서의 데이터를 뿌려주고 손쉽게 그 형태를 통해서 관계를 파악 할 수있다.
아까 그 위의 데이터프레임에서, AT&T와 Verizon의 일간 수익률 사이의 상관관계 코드 예제를 보자.
#일단 책에 있는 코드 그대로 가져왔다.
##x축 y축, 사이즈랑 마커 설정 후
ax = telecom.plot.scatter(x='T', y='VZ', figsize=(4, 4), marker='$\u25EF$')
#라밸링해주고
ax.set_xlabel('ATT (T)')
ax.set_ylabel('Verizon (VZ)')
#산점도의 색과 크기 정해주면
ax.axhline(0, color='grey', lw=1)
ax.axvline(0, color='grey', lw=1)
plt.tight_layout()
plt.show()
두 주식은 거의 (0,0에 몰려있는 것 처럼 보이지만, 양의 상관관계를 보여준다.
1사분면과 3사분면에 가장 많은 데이터가 뿌려진 것으로 보아 오를때 같이 오르고 내려갈때 같이 내려가는 추세를 띈다고 말 할 수 있다.
'Machine Learning > Practical Statistics' 카테고리의 다른 글
| [Practical Statistics] 데이터와 표본분포 (0) | 2022.03.20 |
|---|---|
| [Practical Statistics] 두 개 이상의 변수 탐색하기 (0) | 2022.03.19 |
| [Practical Statistics] 이진 데이터와 범주 데이터 탐색 (0) | 2022.03.12 |
| [Practical Statistics] 데이터 분포 탐색하기 (0) | 2022.03.04 |
| [Practical Statistics] 변이 추정 (0) | 2022.03.03 |