
난생 처음 뇌 mri, mra 두개 다 찍어봤다.
이석증이라고 생각했지만, 이석증이랑은 좀 다른 증상이 보여서 혹시 모르니 찍자고..
처음에는 큰 병인가 라는 걱정이 먼저 들다가,
청구비용 너무 비싸서 짜증났다가,
mri기계 들어가서 곰곰히 생각해보니 내가 언제 나의 뇌를 구경하겠나 싶은 이상한 생각이 들었닼ㅋㅋ
암튼.. 일단 약으로 버티고 있긴한데,
뜬금없이 다 회복했으면 좋겠댜.
(검사하고 아무것도 안나와야 좋은거니까)
선형회귀 - 보험료 예측하기
지난번에 말했던 것 처럼 선형회귀는 여러 가지 데이터(변수)를 활용하여 연속형 변수인 목표 변수를 예측하는 것이 목적이다.
선형 회귀 모델에서는 예측할 종속변수만 연속형 변수되고, 나머지 예측하는데 사용하는 변수들의 경우는 연속적일 필요는 없다!
책이 프로세스를 아주 깔끔 하게 정리해준 덕에, 나도 좀 깔끔하게 정리 할 수 있을 것 같다.
1. 문제정의
사람마다 다르게 책정되는 보험료이고 계산하는데 상당히 복잡하다.
즉 다양한 독립변수 (나이, 성별, BMI, 자녀수 흡연)을 활용하여 종속변수인 병원 비용을 예측해장.
-> 보험 데이터 셋을 이용해서 보험사에서 청구할 보험료 예측
2. 라이브러리 및 데이터 불러오기
기본적으로 import 시킬 라이브러리들을 다 가지고 오고 url을 통해서 파일을 한번에 불러와보자
import pandas as pd
file_url = 'https://media.githubusercontent.com/media/musthave-ML10/data_source/main/insurance.csv'
data = pd.read_csv(file_url)
data
귀엽고 앙증맞은 1338개의 데이터가 나온다.
3. 데이터 확인하기
책에서 언급된것처럼 기본적으로 예제 데이터 셋이 이쁘기도하고 첫장이니까 정리가 된 데이터 셋을 사용한다고 한다.
즉 추가적인 클리닝 작업이나 피처 엔지니어링을 생략하니까 간단히, 흔히 파이썬 배우면 하는 그 통계치들과 값을 확인해보고 넘어가쟈.
round(data.describe(), 2)
data.info()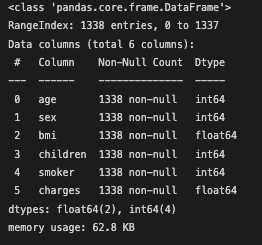
정말 이쁘고 깔끔한 null값이 전혀 없는 데이터 셋이댜...
4. 전처리: 학습셋과 시험셋 나누기 (Train_set, Test_set)
혼공머신에서도 하듯이 항상 머신러닝을 하려면 머신을 학습 시켜야한다.
학습시킬 트레이닝셋과, 평가를 할 테스트 셋을 나누어줘야하는게 가장 기본 순서이다.
추가적으로 데이터를 나누는 작업은 2가지 차원으로 진행이 된다고 말하는데,
- 첫째는 종속변수와 독립변수의 분리
- 둘째는 학습용과 평가용 set을 나누는 것
즉 2x2로 생각하며 4개의 데이터셋으로 분리가 된다.
| 독립변수 | 종속변수 | |
| 학습셋 (Train_set) | X_train | y_train |
| 시험셋 (Test_set) | X_test | y_test |
이렇게 나누는 이유는 훈련 시킨다고 간단히 말을 하긴 했지만,
기본적으로 지도학습을 쓰는 것을 생각한다면, 모델링할 때 어떤 변수가 종속변수(예측하고싶은 값)인지를 정확히 지시해줘야한다.
데이터를 나누어주고 새로운 데이터를 받아 평가하는 것이 당연하게도 맞는 말이기 때문에 나누어주는 것이 맞댜.
개인적으로 예전에 혼자 진행했을때도, 대부분의 책에서도 그렇듯이 학습셋:시험셋의 비율으 7:3 혹은 8:2 정도로 하는데,
예전에는 흔히 뭐 그렇게 하니까 걍 나누었다면 이 책에서는 조금 더 다른 이야기를 해준다.
핸들링하는 데이터가 어떤 양인지에 따라 비율 조절이 필요할 수 도 있다.
즉 데이터의 크기가 작은 상황이라면 학습셋의 비율을 높혀서 최대한 학습셋을 많이 확보해야하는 것이고
반대로 데이터가 너무 많은 상황이라면 6:4, 혹은 5:5의 경우도 가능하다고 한다.
비율 자체가 경험적으로 판단하는 (즉, 여러번 그 도메인 데이터에서 활동을 하고 분석을 한 그런 감?) 영역이기 때문에 무엇이 정확하다라고 말하기 어려운것같다...
4-2. 데이터셋 나누기
위에서 이유를 알았으니, 바로 데이터 셋을 나누어보쟈.
# step 1: 독립변수와 종속변수 나눠주고
X = data[['age', 'sex', 'bmi', 'children', 'smoker']] #독립변수를 만들어주고
y = data['charges'] #구하고자하는 종속변수를 설정한다
# step 2: 학습셋과 시험셋을 나누어줄 모듈
from sklearn.model_selection import train_test_split
# step 3: 데이터셋을 이제 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.2, random_state= 100)step1에서는 독립변수로 사용할 컬럼들을 X로 지정을 해주고
원하는 값 (y)인 종속 변수(보험비용)을 y로 설정해주었다.
step2에서 학습셋과 시험셋 나누어 줄 수 있는 모듈을 불러와서
step3에서 적용해주었따.
함수인 train_test_split 자체가 4개의 데이터셋을 만들어주기 때문에 좌항에 4개의 변수들이 들어있는 것이이다.
test_size의 경우 위에서 언급했던 학습셋과 테스트 셋의 비율을 설정하는 것인데, 테스트를 0.2로둔다면 8:2로 한다는 의미이다.

그리고 random_state 는 random sampling에서의 기준점?이라고 생각하면 쉽다.
전체적인 데이터셋에서 순차적으로 80%를 훈련 시키는것도 말이 안되고, (혼공머신에서 다뤘었다)
그런 이유로 랜덤하게 80%의 훈련데이터를 추출해주어야 하는데 그부분을 함수인 train_test_split에서 벌써 해준다!
그럼 random_state를 설정하는 이유는 계속 매번 실행할때마다 랜덤값이 달라지는 함수이기 때문에 그것을 고정시켜주는 방식?이라고 하면 좀 쉽다.
예를 들어 나의 코드를 누군가와 공유할때에, random_state를 지정하지 않는다면 계속 값이 달라지는 상황이 있기 때문에 같은 랜덤값을 가지게해주는 그런 옵션이라고 보면 된댜.
여기서 100을 넣었으니 나도 100을 넣으면 책과 동일한 결과를 가지고 올것이다.
5. 모델링
모델링이라는 것은 머신러닝 알고리즘으로 모델을 학습시키는 과정이고, 그 결과물이 머신러닝 모델이 된다고 보면 된다.
모델링에서는 우선적으로 어떤 머신러닝 알고리즘을 사용할지 선택하고, 독립변수와 종속변수를 fit()함수에 인수로 넣어주고 학습한다.
fit()함수라는것은 간단하게 모델을 학습을 시켜주는 함수라고 생각하쟈.
# 모델링
from sklearn.linear_model import LinearRegression #선형 회귀 라이브러리 불러오고
model = LinearRegression() # 선형회귀로 학습할 모델이름 설정하고
model.fit(X_train, y_train) #fit함수에 독립변수와 종속변수를 넣어준댜
6. 모델을 활용해서 예측하기
예측을 하기전에 원래는 예측 및 평가에서 학습셋과 시험셋이 오버피팅 문제를 확인해주는 작업이 필요한데, 추후에 더 디테일한 과정을 다루니 여기선 스킵한다고 한다.
(너무나 이쁜 데이터를 넣었잖아!)
predict()라는 함수로 예측을 하였고, 괄호 안에는 예측 대상을 넣어준면 된다.
나중에서는 독립변수가 하나라도 빠진 데이터로 예측을 한다면 큰 오류가 생길 수 있는점 정도는 알고 넘어가쟈...
# 예측하기
pred = model.predict(X_test)
pred
값을 보면 일단 예측치를 각 데이터별로 가지고 왔는데 평가하는 방법을 통해서 해석해보쟈.
7. 예측 모델 평가하기
모델을 평가하는 방법은 다양한데, 여기서 먼저 다루는 평가방식은 테이블, 그래프, 그리고 통계적인 방식으로 평가를 한다.
테이블로 평가
테이블로 평가한다는 걸 보고 눈을 좀 의심했는데, 단순하게 볼때는 뭐 그럴 수 있지만 대부분의 경우 테이블을 보고 판단하지 않는다..
일단 예측한 값은 위에서 본것처럼 pred라는 값에 잘 들어가있고, 각 관측체에 대한 실제 정보는 y_test에 저장이 되어있다.
예측값이 얼마나 정확한지 알려면 pred의 값과 y_test를 비교하면 되는데 두 데이터를 합쳐서 비교를 해보자.
# 테이블로 모델 비교해보기?
comparison = pd.DataFrame({'actual': y_test, 'pred': pred}) # y_test, pred모두 리스트 값이기 때문에 df화를 시켜줘서 보려고 pd.DataFrame을 사용한다
comparison
첫번째 행을 보면 실제 값은 1826.84300이지만 예측값은 4765.249466이다.. 차이가 엄청 커보이는데
맨 아래에 있는 행에서는 실제값이 12124.99240이고 11638.26000으로 큰 차이가 없다라고한다.
(대충 비교해보면 첫번째 행은 약 60%의 오차, 마지막 행은 4%정도 오차가 나니까....)
이렇게 일일이 비교하는건 쉽지 않으니 바로 다음 단계인 그래프로 평가하는 방식을 보쟈.
그래프로 평가
대부분 파이썬에서 그래프 그리면 matplotlib이나 seaborn이런거 많이 쓰는데 여기선 오 둘다 쓰네.?
바로 임포트 시켜서 산점도 간단히 그려보자.
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(10,10))
sns.scatterplot(x = 'Actual', y='Pred', data= comparison)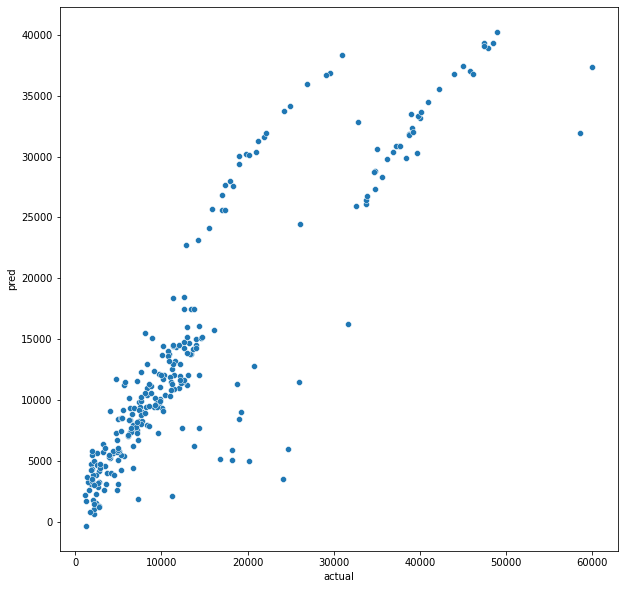
데이터 참 특이하게 나오긴 했는데, 책에서는 3그룹으로 나누어져있는 데이터를 보고 그룹별로 해석을 해주셨다.
예측값과 실제값 1:1인 라인을 통해서 3그룹으로 분류해서 설명을 해줬는데, 나도 그럼 그냥 파이썬에서 1:1라인도 그려주기로 했다.
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(10,10))
#책에서 나온 것 처럼 실제값과 예측값이 정확히 같은 1:1라인도 같이 그려주고
plt.plot([0, 50000], [0, 50000],color="green", linestyle = '--')
sns.scatterplot(x = 'actual', y='pred', data= comparison)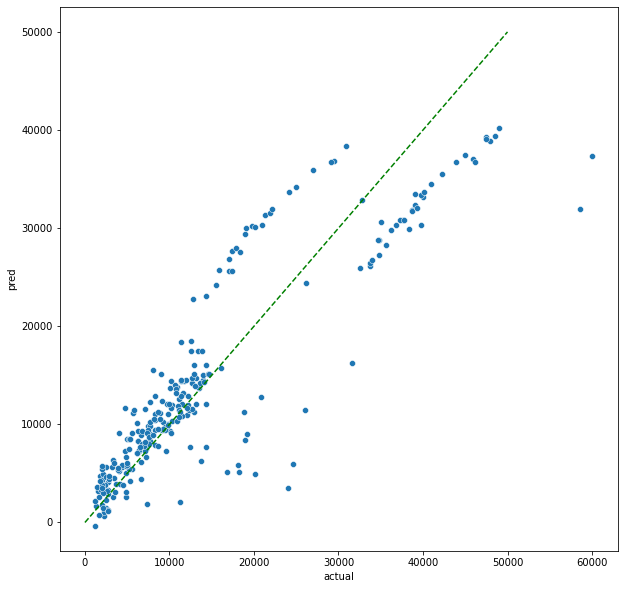
그룹이 조금씩 나뉘긴 하는데 1:1 라인을 기준으로 보았을때 좌측 하단에 있는 그룹군은 비교적 예측이 잘 된것처럼 보인다.
1:1라인 위로 나열된 그룹군의 경우에는 실제값보다 예측값이 높다는 것을 의미하고,
아래 그룹은 실제값보다 예측값이 더 낮은경우다.
이런식으로 테이블보다는 훨~씬 더 수월하게 판단이 가능하다.
하지만 시각화라는 것은 직관적으로 보는거지 객관적이지 않는다는 것을 명심해야한다..
(책에서는 없지만 회귀선 그려보고싶어서 걍 개인적으로 그려봄. 산점도를 그렸는데 회귀선은 봐야지..)
# scatterplot과 라인도 같이 그려보고 싶었드..
plt.figure(figsize=(10,10)) #사이즈를 먼저 지정해주고
# regplot을 사용하고 fit_reg를 지정하면 회귀선을 쉽게 볼 수 있다!!!
sns.regplot(x=comparison['actual'], #형식은 df에서 가지고 오는 것이기 때문에 df['']형식으로 x,y설정하고
y=comparison['pred'],
fit_reg=True
) # default
#책에서 나온 것 처럼 실제값과 예측값이 정확히 같은 1:1라인도 같이 그려주고
plt.plot([0, 50000], [0, 50000],color="green", linestyle = '--')
plt.title('Scatter Plot with Regression Line by regplot()', fontsize=15) # 시각화 자료의 이름도 걍 씀
plt.show()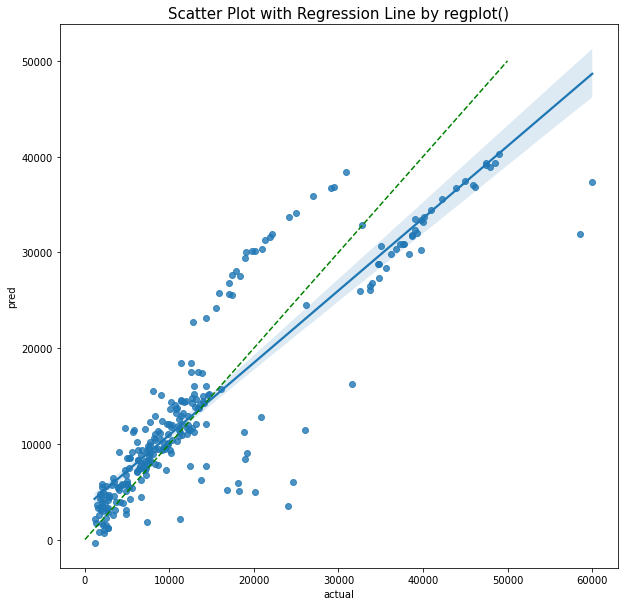
통계적 방법으로 평가하기: RMSE, MSE, MAE, R^2
그럼 좀 더 객관적으로 평가하려면, 통계적인 방식을 사용하면 수월하다.
흔히들 연속형 변수를 예측하고 평가할때 많이 쓰는 RMSE를 알려주는데 (Root Mean Squared Error),
간단히 생각하면 실젯값과 예측값 사이의 오차를 각각 합산하는 개념이라고 생각하면 쉽다.
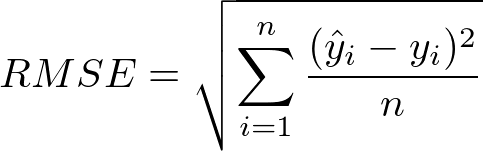
공식만 봐도 알겠지만, Euclidean Distinace 공식에서 n나눠준것이랑 같다.
https://towardsdatascience.com/what-does-rmse-really-mean-806b65f2e48e
What does RMSE really mean?
Root Mean Square Error (RMSE) is a standard way to measure the error of a model in predicting quantitative data. Formally it is defined as…
towardsdatascience.com
기존에 분명 내가 한번 다룬것같긴한데, 이 아저씩 기초적인 개념부터 잘 설명을 해주셨으니 한번 보고 오면 이해가 쉽다.
(Practical Statistics에서 분명 다룰 것인데 나중에 링크 붙혀놔야겠음)
예들들어,
각 데이터셋에서 가지는 오차가 동일하다고 하더라도, 오차에 제곱을해버린다면 값이 확연히 다를 수 있다.
그래서 오차가 더 클때에 큰 패널티?를 주려고 제곱의 차이를 이용한다.
특히, 제곱을 사용하는 수식의 장점 자체는 미분이 가능하다는 것이고, 추후에 다루겠지만, 경사하강법에서 기본이 되는 내용이니 일단 알고 넘어가자.
조금 더 디테일한것까지 하나씩 잡아주는데,
- MAE(Mean Absolute Error): 평균 절대값 오차로 절대값의 차이를 이용하는 방식
- MSE(Mean Squared Error): 평균 제곱 오차라고 하며, 제곱의 차이를 이용하는 방식
모두 차이의 합을 총 개수로 나누고 평균을 내기 때문에 Mean을 사용한다.

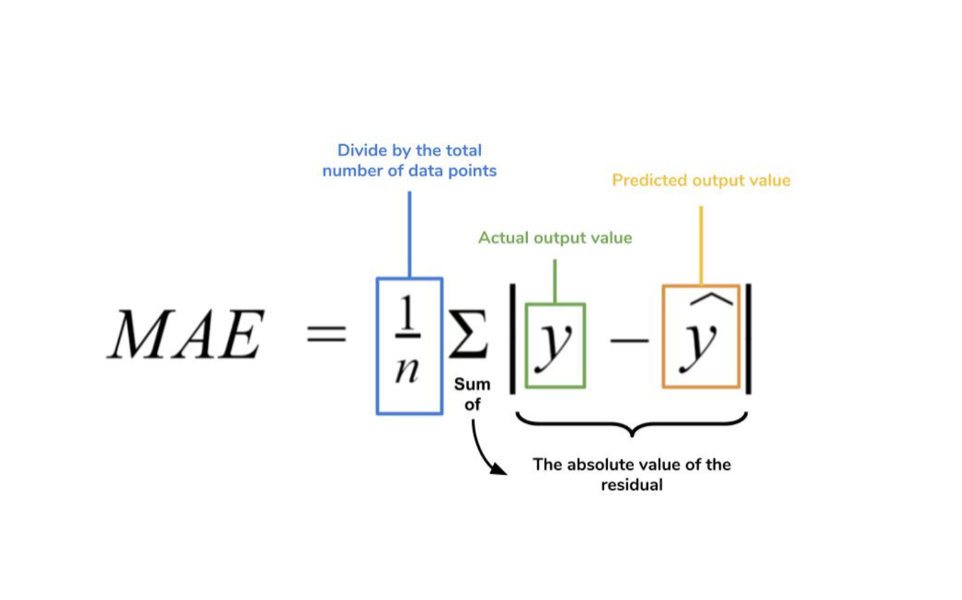
보통 MAE보다 MSE를 흔히 사용한다고 하는데,
MSE가 가지는 단점은 제곱으로 인해서 그 숫자의 규모가 실제 데이터 스케일에 비해서 커져버리는 것이다.
그렇기 때문에 MSE에 루트를 씌워준다면, 스케일도 맞아 떨어지고 그것이 즉 위에서 본 RMSE가 되는 것이댱.
다시한번 정리하고 가면,
| 평가지표 | 설명 |
| MAE | 평균절대오차, 실제값과 예측값 사이의 오차에 절대값 씌우고 평균 계산 |
| MSE | 평균제곱오차, 실제값과 예측값 사이의 오차를 제곱하고 평균을 계산 |
| RMSE | 루트평균제곱오차, MSE에 루트 씌우고 가장 일반적으로 사용됨 |
세가지 지표 모두 값이 작을수록, 즉 0에 가까울 수록 좋은 지표를 가진다고 말할 수 있댜.
개념 알았으면 코드 날려봅시다.
from sklearn.metrics import mean_squared_error # MSE라이브러리를 임포트 시켜주고
# solution 1
mean_squared_error(y_test, pred)**0.5 #RMSE에 루트를 씌워주는 방식 (**0.5)는 0.5에 제곱해주는 의미
# solution 2
mean_squared_error(y_test, pred, squared=False) #square라는 매개변수를 False로 설정하면 rmse를 바로 구할수 있음5684.927776334486
값이 5684.. 라고나오는데 이게 좋은값인가? 라는 의문이 당연히 든다.
위에서는 0과 가까울 수록, 값이 작을 수록인데 작다고 말할 수 있나??
아니지, 이건 알수 없는거다 왜냐면 비교할 대상이 없기 때문이다.
그래서 보통 RMSE는 절대평가가 아닌 상대평가 지수라고 생각하면 된다.
아니 그럼 절대평가지수는요?
예 그래서 R^2(결정계수)를 사용하면 됩니댜.
R^2라는 지표는 독립변수로 설명되는 종속변수의 분산 비율을 나타내는 통계적 측정값이다.
(학부때 손으로 일일이 계산하고 했었는데,,, 정말 오래전 이야기다)
대부분 사람들이 r^2 높다고 하면 그냥 좋은 결과가 나왔고 예측을 잘 했네 하지만,
개인적으로는 근본,, 각 지표가 정확하게 의미하는 바를 확인하는게 더 중요한것같다.
공식 먼저 보고 차근차근 봐보자.
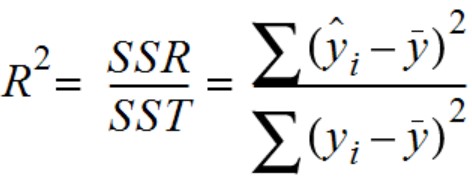
위의 공식에서 말하는 것 처럼 SST, SSR 라고 씌여진 것도 있고, 다른 자료들에서는 ESS, RSS 이라고 쓴 경우도 있는데 둘다 동일하다고 생각하면 된댱. (영어 순서의 차이)
위 공식과 아래의 이미지를 같이 보고 이해하면 훨씬 머리속으로 이해하기 쉽다.
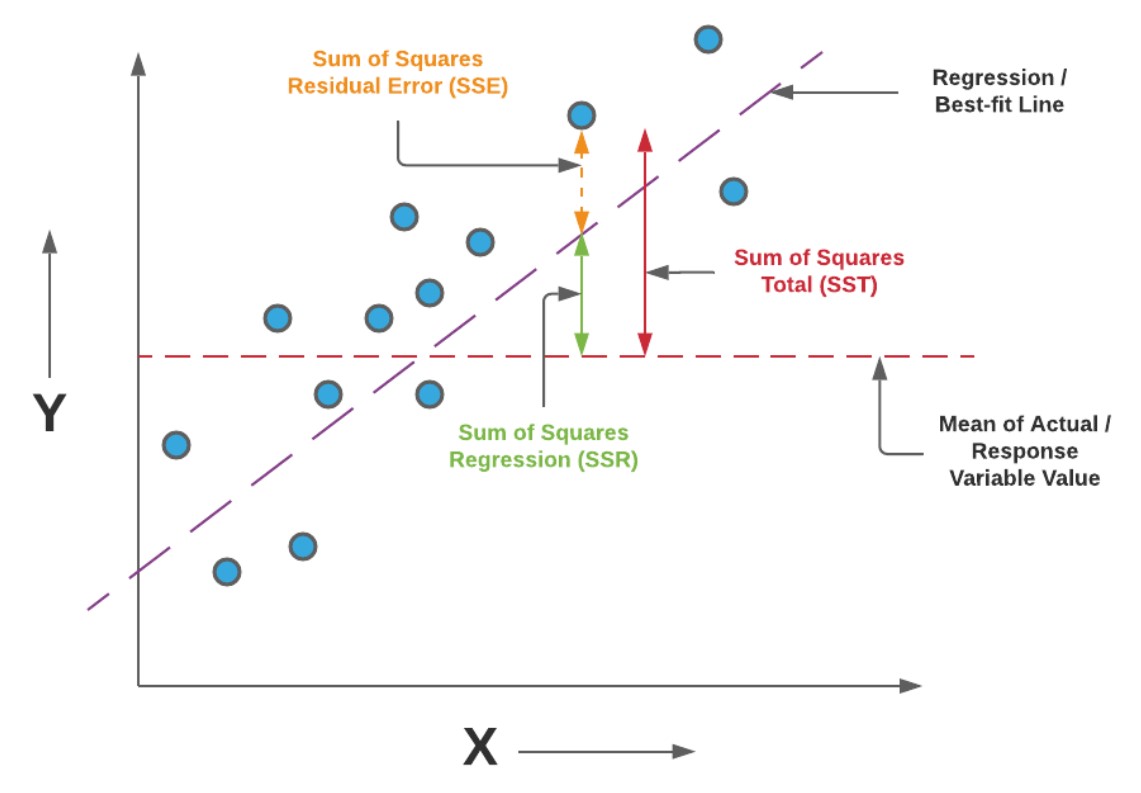
위에서 보이는 SST(sum of squares total) 먼저 보자면 관측된 데이터와 중앙에 종속변수 y의 평균값까지의 거리를 뜻하고
SSR(sum of squares regression)의 경우 종속변수 y의 평균값과 예측된 선형 회귀 라인의 거리를 뜻한다.
(다시말해 평균으로 때려맞춘것과 모델의 차이를 말하는 것이다)
위에 SSE(sum of squares error)의 경우는 모델라인과 실제 데이터까지의 거리, 즉 모델이 예측하지 못한 에러(오차)라고 생각하면 된다.
다시 공식을 곱씹어보면,
R^2는 SST에서 SSR이 차지하는 비율을 말하는 것이다.
순화하면, 예측값과 실젯값 차이중 모델이 얼마만큼 비율로 실젯값에 가깝게 예측하는지를 의미하는 것이라고 이해하자.
#R^2값 계산 코드
model.score(X_train, y_train)0.7368220127747351
0.73이라는 수치가 나오는데, R^2값이 최대 1인것을 감안한다면 0.7~0.8 이상의 값을 가지면 일반적으로 나쁘지 않은(괜찮은)수치라고 판단한다.
8. 이해하기: 선형회귀
내가 책을 산 이유중에 이 부분이 가장 맘에 들어서 샀다.
단지 뭐 코드만 주구장창 늘어놓고 대충 끝내는 것이 아니라 기본적 개념을 한번 잡고 마무리해줘서.
위에서 간단히 진행했던 선형 회귀 모델은 독립변수와 종속변수간에 선형 관계가 있음을 가정하여 최적의 선을 그려 예측하는 것이다.
위에서 내가 선형라인을 보면 파란색으로 범위가 살짝 보이는데 내가 그린 선형 라인에서 기본적으로 95신뢰구간을 그려주기 때문이다.
사실상 기본적인 셋팅을 하지 않으면 100%짜리인 하나의 선이 나오겠지.
plt.figure(figsize=(10,10)) #사이즈를 먼저 지정해주고
# regplot을 사용하고 fit_reg를 지정하면 회귀선을 쉽게 볼 수 있다!!!
sns.regplot(x=comparison['actual'], #형식은 df에서 가지고 오는 것이기 때문에 df['']형식으로 x,y설정하고
y=comparison['pred'],
fit_reg=True,
ci =None #confidence interval (신뢰구간을 없애면 한줄 )
) # default
plt.title('Scatter Plot with Regression Line by regplot()', fontsize=15) # 시각화 자료의 이름도 걍 씀
plt.show()
sns.regplot에서 ci (confidence interval)을 none으로 지정하면 한줄만 나온다.
사람이 보기에는 어떤 선을 그릴지 알기 쉽지 않지만 위에처럼 모델을 사용할 경우 자기가 알아서 손실함수(Loss Function)을 최소화한 선을 찾아 모델을 만들어준다.
손실함수는 예측값과 실젯값의 차이, 오차를 평가하는 방법이라고 생각하면된다.
위에서 다 정리했던, MSE, RMSE가 여기서 손실함수를 의미한다.
선형회귀는 단순해서 수식으로도 쓰기 편하다.
(단순해서 학부때 다 손으로 했는데, 사실 단순하지만 노가다임. 정말 귀찮을정도로 손이 많이감. 손으로 풀진 말자..)
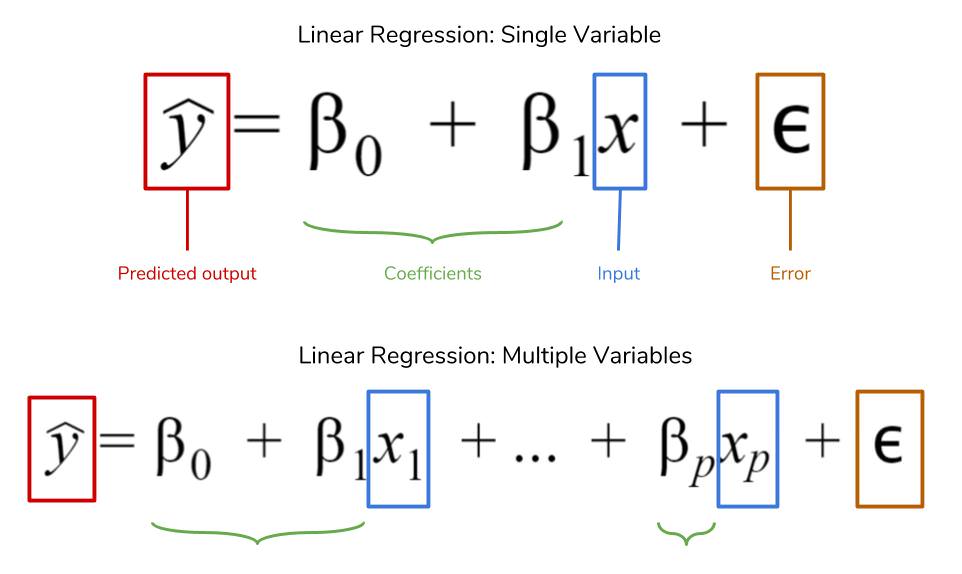
일차원의 라인을 그려주는 것이기 때문에 1차함수 수식으로 간단히 표현이 가능하다.
위의 공식을 보았을때 x의 경우 각 변수(feature)이고, beta값들에는 각 변수가 가지는 계수다.
beta_0의 경우는 y절편이다.
x의 경우 우리가 위에서 사용했던 feature니까 [age, sex, bmi, children, smoker] 가 되겠고
yhat의 경우에는 charge가 되겠지.
책에서는 언급이 없었지만 위의 공식을 보면 epsilon (error)가 있다.
epsilon의 경우는 오차항, 노이즈를 뜻하는 것인데 해당 저 변수는 종속변수 y에 대한 모든 오차를 포함하고 있다만,,
실제로 대부분의 y값이 가지는 오차(노이즈)를 정확하게 추출 할 수가 없기 때문에 대부분의 공식을 보면 epsilon은 제거한다.
그럼 각 변수가 가지고있는 계수를 한번 확인한다면 아름다운 수식을 하나 만들 수 있지!
# coef_의 형테는 넘파이 형태로 출력이 되기 때문에 판다스 형태로, 그리고 X.에 해당되는 각 컬럼별 계수를 확인
pd.Series(model.coef_, index = X.columns)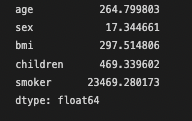
아름다운 수식 만들기 전에 해석을 해야하는게 우선이다.
age의 경우 연속적인 정수형태이니까, 1이 증가하는 만큼 chargesRrk 254.8만큼 증가한다고 이야기 할 수 있다.
근데, sex나 smoker의 경우는 0, 1 이런식의 데이터이기 때문에
1만큼 증가한다고 17이 늘어나는 것이 아닌,
남자(1)의 경우 여자(0)인 경우보다 17정도 높다라고 해석을 해야한다.
y절편도 한번 봐야지
# 모델에서의 intercept, y절편값
model.intercept_-11576.999976112367
아름다운 수식 적어보면,,
charges = 265.8*age + 17.3*sex + 297.5*bmi + 469.3*children + 23469.3*smoker -11576.9
이런식이다.
마무리
보험 데이터 셋으로 보험료를 예측하는 모델을 간단하게 만들었는데, 기본적인 모델이고 복잡하지는 않았지만
프로세스를 익히고 감을 잡는데는 충분히 도움이 되었다.
아 그리고, 모델을 비교할때 유의할 점은 각 여러 계수를 비교할때 단순히 절댓값이 더 크다고 영향력이 있는 것은 아니다.
각 변수의 스케일 자체가 다르기 때문이다.
그렇기 때문에 스케일링 작업이 필요하고 이런 경우 K-최근접이웃에서 다시 다룬다. (혼공머신에서도 스캐일 강조했음)
선형회귀와 관련 모델로는 릿지 회귀(L2), 라쏘 회귀(L1), 엘라스틱 넷 등 다양한 모델들이 있는데,,
선형 회귀 모델에 정규화를 적용한 모델들로 오버피팅이나 피처셀렉션을 억제하거나 단점을 보완한 모델들이다..!!
(일주일 전에 이거 봤어도!!! ㅠ)
뒤에 디테일하게 설명하는 부분을 미리 공부했는데, 상당히 깊히있게 잘 설명하고있어서 지금 다루진 않겠땨.
책 아주 정말 잘 샀다는 생각이 든다.
혼자 독학하는 사람으로써는 아주 굳굳.
컨디션 더 좋아지면 더 열심히해야지.
'Machine Learning > ML - 데싸노트' 카테고리의 다른 글
| [데싸노트] 로지스틱 회귀 - 타이타닉 생존자 예측하기 (0) | 2022.11.20 |
|---|---|
| [데싸노트] Top 10 알고리즘 (0) | 2022.11.07 |