
요양을 다녀왔는데, 큰 효과는 없다..
어질어질 거리는건 몸을 움직일때마다 멀미가 난다.
그치만 또 약 먹으면, 효과가 강력!!!해서 그시간에 운동 겁나하고 있고, 짬내서 막 블로그 좀 하고 책이라도 보는거지...
(쉬어야할때 안쉬는 미친넘이라는 소리를 또 들었음..)
몸 진짜 완벽하게 회복 하면 다시 운동에 미친넘 처럼 살면서, 열심히 공부하고, 열심히 놀면서 하루를 아깝게 보내지 않을거다....부들
1. 문제 정의
데이터 분석 조금 해봤다 하는 사람들은 모두 써봤던 그 데이터셋, 타이타닉 데이터 셋이다.
책이나 뭐 예제들 수없이 보고 사용하고 했는데, 내가 스스로 분석하는건 처음이다..(붓꽃데이터 역시 안해봄 ㅋ)
암튼 승객 정보에따라 생존에 어떤 영향을 미치는지 파악하는것이 목적이다.
2. 라이브러리 및 데이터 불러오기
기본적으로 불러오는건 지난번과 동일하고 파일 이름만 다르다.
import pandas as pd
file_url = 'https://media.githubusercontent.com/media/musthave-ML10/data_source/main/titanic.csv'
data = pd.read_csv(file_url)
data
3. 데이터 확인하기
data.info()
이번데이터 셋도 역시나, Null값이 전혀 없는 깔끔한 데이터 셋이다.
Dtype이 object인 문자형 변수 4개가 눈에 띄는정도.
data.describe()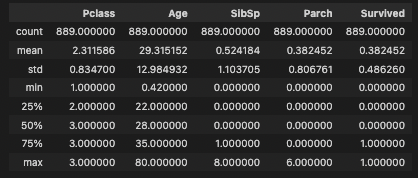
describe()를 통해서 object가 아닌 숫자형 변수들의 통계값을 살펴본다면
Pclass는 3개의 값을 가지고 , 나이의 범위나, SibSp(함께 탑승한 형제 및 배우자 수), Parch(함께 탑승한 부모 및 자녀의 수)의 특징을 볼 수 있다.
마지막 Survived는 우리가 예측할 종속변수의 값.
여기서는 상관관계를 통해서 조금 더 깊게 나아가는데, 지난 포스트들에서 상관관계 관련해서 많이 했었기에 책의 시각화 코드가 아닌 과거 자료 코드로 해보겠댜.
일단 상관관계 지수 먼저 파악해보자면,
round(data.corr(), 3) #소숫점설정
뭐 생각보다 크게 상관관계가 있다고 할만한 변수관계는 없어 보인다.
그나마 Parch와 SibSp의 관계가 0.415정도로 가장 높게 나왔는데... (굳이 시각화 한다니까 해봅시댜)
과거 상관관계 포스팅을 참고해서 그려보자.
https://simbbo-blog.tistory.com/135
[Practical Statistics] 상관관계
상관관계 상당히 자주 그리고 많이 사용했었던 상관관계다. 업무 특성상 과연 이게 상관관계가 있는건가?라는 의문을 던지고 확인 하는 일이 많다. 다양한 방법이 있지만, 데이터에서 상관관계
simbbo-blog.tistory.com
#그래프 그려줄 라이브러리
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
#히트맵도 잘 보이지만, 책에 나온 방식이 아닌 다양한 방식으로 상관관계 지표 구해줄 수 있다.
data = data.corr()
fig, ax = plt.subplots( figsize=(14,14) )
# 삼각형으로 짤라서 보면 편함
mask = np.zeros_like(data, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
# 히트맵을 그린다
sns.heatmap(data,
cmap = 'RdYlBu_r',
annot = True, # 실제 값을 표시한다, 실제 숫자값이 나와야 난 보기가 좋았음
mask=mask,
linewidths=.5, # 경계면 실선
cbar_kws={"shrink": .5},
vmin = -1,vmax = 1
)
plt.show()
시각화야 보기 나름이고 하기 나름이라서, 정답은 없지만 다양한 방식이 있으니 뭐 이런저런 방식 여러개 해보면 될듯하댱.
4. 전처리: 범주 변수 변환하기(더미 변수와 One-Hot 인코딩)
이번 포스트에서 가장 집중하고 싶은 부분중에 하나다.
인코딩 하는 방식과 전처리가 참 힘들고 고되고 머리 아프고 하지만 가장 중요하니까.
(공부를 안한다고 하더라도, 지금도 매일 멀미하는 느낌이 있다...)
지금 다루고 있는 데이터 셋에서는 object의 변수가 4개 있다.
기본적으로 일단 머신러닝 알고리즘에서는 문자열로 된 데이터를 이해할 수 없기 때문에 머신이 인식하고 학습할 수 있는 형태로 변환을 해주어야 한다.
이런 과정을 인코딩(Encoding)이라고 하며, 여러 방식이 있다.
일단 최근 회사에서 작업하고 공부하는 부분이 인코딩쪽이라서 정리하는걸 좀 나열해보겠다.
- Label Encoding:
- 가장 흔하게 하는 인코딩 형태로 n개의 종류 값들을 0에서 n-1개의 값으로 숫자를 부여한다. 이 숫자에서는 관계가 존재하는것을 까먹으면 안된다!
- Ordinal Encoding
- 순서형 자료에 가장 적합한 인코딩 방식이며, 데이터의 범주형 변수말고도 알파벳 순서도 고려를 해준다고 한다. 직관적인 코딩을 좀 해줄 필요는 있음
- One-hot encoding
- 책에서도 언급하고 대부분 사람들이 흔히 쓰는 인코딩 방식이다
- 각 범주형 변수의 값들을 1과0으로 맵핑 시키는 것이다. 즉 변수에 해당하면 1, 해당하지 않으면 0으로 숫자를 채워 나가는 방식이고 'Dummy'변수를 만든다고 부른다.
- 추가로 분류 문제에서는 n개의 카테고리값에서는 n개 카테고리 모두 인코딩 해주고, 회귀문제에서는 n-1개의 카테고리값을 인코딩 해준다.
- 카테고리컬한 범주 값이 많아질수록 모델링 학습 속도가 느려지는 경우가 있음..
- Binary Encoding
- 이름처럼 범주형 변수들을 이진법을 사용하는 인코딩이다. 즉 n개의 종류를 인코딩 하면 log2의 n제곱만큼 변수가 추가 생성 된다.
- One-hot인코딩보다 더 적은 갯수의 변수가 생성되기 때문에 수행 속도가 빠른 장점이 있다.
- Frequency Encoding
- 변수 값들의 빈도수에 기반해서 인코딩 하는 방식이다.
- 즉 범주형 변수 빈도값이 종속변수와 연관이 있다면 모델이 가중치를 부여하도록 도와주게 되는것
- Mean Encoding
- Target-Encoding이라고도 불러진다.
- 범주형태의 독립변수들이 종속변수값과 상관관계가 있을 거라고 가정하는 것이 특징이다.
- 데이터 양에 영향을 미치지 않고 빠른 학습이 특징이지만, Overfitting 될 문제가 있다는 것을 알아야함
- Kaggler들이 만들었다
참고로 이 분의 포스팅을 기반으로 정리하였고 내가 나열하지 않은 다양한 방식들도 더 많다..!! 꼭 한번은 읽어보길.
https://towardsdatascience.com/all-about-categorical-variable-encoding-305f3361fd02
All about Categorical Variable Encoding
Most of the Machine learning algorithms can not handle categorical variables unless they are converted to numerical values and many…
towardsdatascience.com
인코딩에 좀 집중해 보았던게, 정말 많은 데이터와 그리고 너무나 다양한 모델링, ML기법들이 있는데
인코딩을 하나만 한다는게 이상해서 하나하나 찾아봤고, 회사사람들 주변 지인들이랑 의논 한 뒤에 생각이 다시 잡혔다.
그냥 one-hot encoding이 좋아서 빨라서, 다 쓰니까 이런 이유로 내가 선택하는게 너무 이해가 안갔기 때문에...
암튼 결론은 모델에 맞는 인코딩방법, 그리고 데이터 셋에 맞는 인코딩 방식을 사용하는것!!
그리고 꼭 모든 컬럼들을 인코딩 하는 생각을 하면 안된다.
버릴건 버리고 이쁘고 아름다운 셋을 만들어야하는것!.. 이런 과정이 정말 분석 과정에서 85%는 차지하는 느낌이다 ㅠ
암튼, 다시 책의 내용으로 돌아와서!
타이타닉 데이터셋에 있는 object애들을 봐보자.
Name, Sex, Ticket, Embarked 의 고유값이 얼만큼인지 확인을 해보고 맞는 인코딩 방식을 찾아보는거지.
#고유값 확인하기
print('Name:', data['Name'].nunique())
print('Sex:', data['Sex'].nunique())
print('Ticket:', data['Ticket'].nunique())
print('Embarked:', data['Embarked'].nunique())Name: 889
Sex: 2
Ticket: 680
Embarked: 3
성별이나 승선한 항구(Embarked)도 유니크한 값이 많지는 않은데 이름과 티켓은 너무 많다...
그렇기때문에 데이터를 다시 생각해봐야한다.
이름이랑 티켓이 사망 여부에 갈린다고 판단할수있을까?
이름은 과감하게 제거할 수 있을 것이라고 보여지고, 승선한 항구는 이미 Pclass와 비슷하게 볼 수 있기 때문에 굳이 동일한 느낌의 변수로 먼가 얻어낼 필요는 없어보인댜.
그래서 Name과 Ticket이라는 변수는 제거하고 나머지는 one-hot 인코딩을 하용하기로 한다.
(가장 간단하고 변수도 적었고, 순서형이 아닌 범주형이며, 데이터 셋이 크지 않으니 오케이)
그 전에 데이터에서 쓰지 않을 컬럼을 날리고 작업하기로한다.
#컬럼제거하려면 drop으로 간단히, axis 1=컬럼, 0=행
data = data.drop(['Name', 'Ticket'], axis = 1)
#get_dumies를 통해서 원핫인코딩
# drop_first를 통해서 기존 고윳값개수에서 하나 빼준다. 이유는 데이터 셋을 보면 됨
data = pd.get_dummies(data, columns=['Sex', 'Embarked'], drop_first=True)
data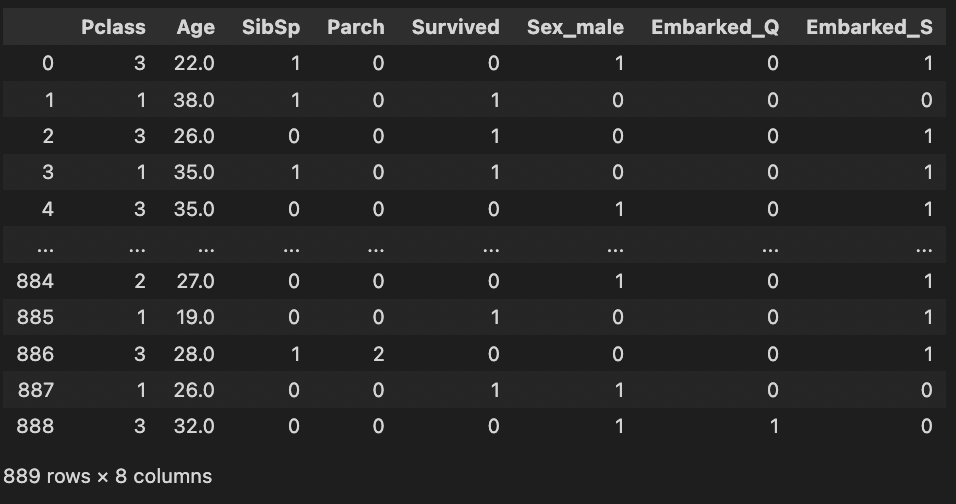
성별은 남자인지 아닌지만 알면 되는 것이고,
Embarked 역시 C클래이거나 Q, S 둘중 하나이기 때문에 굳이 두개의 컬럼 (Sex_female, Embarked_C)를 만들어 줄 이유는 없다.
이정도까지만 하고 모델링 고고!
5. 모델링 및 예측하기
모델링하기 전에 일단
독립변수 / 종속변수, 그리고 훈련셋 / 시험셋으로 나누고 가야지.
from sklearn.model_selection import train_test_split
X = data.drop('Survived', axis = 1) #데이터 셋에서 종속변수 제거후 저장
y = data['Survived'] #데이터 셋에서 종속변수만 저장
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=100)
#로지스틱 회귀 불러오고
from sklearn.linear_model import LogisticRegression
#model에 로지스틱 회귀 분석 속성 넣고 fit()으로 훈련시킨다
model = LogisticRegression() #모델 생성
model.fit(X_train, y_train) #모델 학습
pred = model.predict(X_test)
6. 예측 모델 평가하기
지난 선형회귀에서는 실제값과 예측값의 차이를 합산해서 보는 RMSE를 통해 평가했었다.
하지만 로지스틱 회귀처럼 목표값이 0, 1 로 이루어진 이진 분류에서는 쓸만한 평가 지표가 아니다.
대부분 ML에서의 평가 지표라고 할때는, 정확도, 오차행렬, 정밀도, 재현율 f1 score, 민감도, 특이도 auc커브 이런게 있는데...
일단 여기서는 정확도 하나만 가지고 판별한다고 하니, 나머지 값들은 차근차근 진행해보는걸로 하쟝.
정확도란 말 그대로 예측값과 실젯값을 비교해서 얼마나 맞추는지를 확인하는 것이다.
#정확도 라이브러리 가지고오고
from sklearn.metrics import accuracy_score
#실젯값과 예측값으로 정확도를 계산하면?
accuracy_score(y_test, pred)정확도 하나만 뽑아본건 처음이긴한데, 약 78%의 정확도를 보여주는데, 엄청 좋다고 나쁘다고도 하기 애매하다..
이게 왜 애매하냐고 말하냐면, 자신이 가지고 있는 데이터 셋마다 다른 상황이 다르게 해석되기 때문이다.
예를 들어 0이 95%이상인 이진분류 데이터 셋에서는, 정확도가 90%라도 좋은 값이라 부르기 힘들다...
그냥 대충 때려맞춰도 95%가 0일 수 있기 때문이다.
다른 예로 0, 1 값의 비율이 5:5인 데이터 셋에서 80%정도의 정확도는 나쁘지 않고, 90%의 정확도라면 좋은 결과라고 판단 될 수 있다.
추후에는 이런 0, 1 비율을 샘플링하고 비율을 맞춰주는 기법도 있고, XGBoost, LightGBM을 사용하면 더 좋은 정확도를 가질 수 있다.
그럼 회귀 분석을 했으니, 모델의 계수도 보고 해석을 해보아야 한다.
pd.Series(model.coef_[0], index = X.columns)
Parch값을 제외하면 모두 음수인데,
목표값이 1이였을때 생존이였던걸 생각하고 해석 해보면...
Pclass가 낮은 숫자일 수록 좋은 티켓이라서 좀더 유리하게 나온 느낌?이고
age가 역시 어릴수록, 성별은 여자일 수록 더 가능성이 높다 라고 보여진다.
7. 이해하기: 피처 엔지니어링, 로지스틱 회귀분석
피처엔지니어링
아까 전처리 단계에서 알게 모르게 피처엔지니어링을 한것이다.
피처 엔지니어링 (Feature Engineering)은 기존 데이터를 변형하여 더 나은 변수로 만드는 기법 이라고 하는데
인코딩을 하여 더미변수를 만든 그런게 피처 엔지니어링이다.
특히나 피처엔지니어링을 할때 통계적인 변수나 수치에 따라 컬럼을 조정하고 할 수 도 있지만, 도메인 지식을 활용하는 방법도 목적에 따라 큰 도움이 될 수 있다.
또한 선형회귀랑, 로지스틱 회귀 이런걸 선형 모델이라고 하는데 이런 선형 모델에서는 다중공선성(Multicollinearity) 문제를 주의 해야한다고 한다.
다중공선성이란 독립변수 사이에 상관관계가 높을 때에 발생하는 문제를 말하는데, 보통 이런 경우를 어떤 식으로 판단하냐면
상관계수가 0.9이상으로 무척 크게 나타난다거나
독립 변수의 일부가 다른 독립 변수의 조합으로 표현될 수 있는 경우를 말하기 때문에, 독립변수라고 보기 힘든 피쳐들이 모여있을때 발생한다.
이런 경우에 보통 높은 상관관계를 가지는 변수중 하나를 제거하거나, PCA처럼 차원 축소를 해줌으로써 해결이 가능하다고 하는데,
여기서 PCA (Principal Component Analysis)란 주성분 분석으로, 차원 축소를 통해 데이터간의 독립변수를 줄이는 방식을 말한다.
(추후에 또 설명한다고 하는데, 이런 감칠맛 때문에 빨리 이 책 독파하고싶음....)
자 그럼, 우리가 가진 타이타닉 데이터 셋을 보면 딱 생각나는 변수들이 있을 것이다.
SibSp와 Parch인데, 형제자매와 배우자, 그리고 부모와 자식을 가지는 이 컬럼을 그냥 하나의 Family라는 변수로 만들어 줄 수도 있다.
data['family'] = data['SibSp'] + data['Parch'] #두개의 변수 하나로 합쳐버리기
data.drop(['SibSp', 'Parch'], axis=1, inplace=True) # inplace true는 기존 데이터셋에서 변경을 하는것을 의미하고 , axis=1은 컬럼
data.head()
두개의 변수를 하나의 변수로 변형 시켜주었다.
그럼 데이터 셋이 변경 되었으니 다시한번 평가를 해본다면?!
X = data.drop('Survived', axis = 1)
y = data['Survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=100)
model = LogisticRegression()
model.fit(X_train, y_train)
pred=model.predict(X_test)
print('new data set accuarcy:',accuracy_score(y_test, pred))new data set accuarcy: 0.7921348314606742
아까 위의 결과보다 약 0.012 상승되었다.
이렇게 다양하게 계속 무한 반복의 굴래를 돌면서 변형해보고, 실험하고 다시 구하고 하는게 ml의 삶...
피처 엔지니어링 자체가 정답이 없기 때문에, 모델을 돌리고 평가 스코어를 구하기 전 그 단계까지 오는데에 정말 90% 에너지를 다 쏟는다고 생각하는데, 내가 지금 회사에서 그러고 있으니 머리가 터지지 터져..
(아니 이러니 내가 혼자 머리가 미쳐 돌아가버리느넫[ㅔ랆 ㅣㄴ)

암튼 정신차리고..
로지스틱 회귀
자 위에서 했던 로지스틱 회귀는 그럼 뭔지 개념을 다시 잡고 마무리해보자.
로지스틱 회귀(Logistic Regression)의 정의는 데이터 값에 따라 데이터의 종속변수의 확률을 0에서 1 사이의 값으로 예측하고, 그 확률에 따라 가능성이 더 큰 범주로 분류해주는 지도 학습 알고리즘이다.
지난번 선형회귀 처럼 단순히 예측값을 구하는 것이 아니고 0, 1 이진 분류에서의 예측값을 구하는 것이기 때문에 선형 회귀에서 시그모이드 함수를 사용하여 직선 상태였던 선형선을 곡선으로 바꿔주는 것이다.
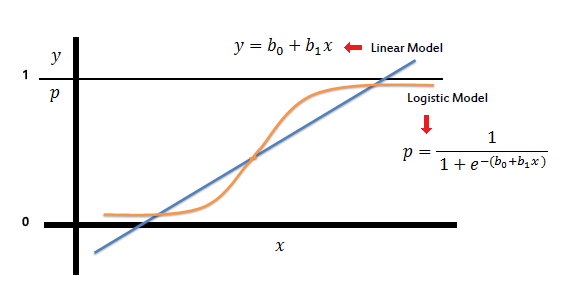
위 그림처럼 linear model에서 시그모이드함수만 사용해주면 깔끔하게 변형 되는데,
시그모이드란 s자 형태의 곡선자체를 뜻하고, 곡선을 그리면서 한없이 0과 1에 가까워지는 형태를 가지게 된다.

아주 쬐금만 더 디테일하게 들어가면
단순선형회귀분석(Linear Regression)은 목표가 실수값 예측이기 때문에 선형함수 를 이용하여 예측이 가능한데,
로지스틱 회귀분석에서는 종속변수가 0 또는 1이기 때문에 예측하는 것은 의미가 없다.
그렇기 때문에 Odds를 이용하는데, Odd라는 것은 이벤트가 발생하는 확률 대비 이벤트가 발생하지 않을 확률이다.

좀 더 간단하게...
저 위의 수식에서 만약에 범위가 0부터 1이라면, 항상 값은 0부터 ∞ 이 나오는데
이분법적인 값을 가지는 로지스틱 회귀에서는 log를 취해 취해줌으로써 값의 범위를 (-∞, ∞) 로 바꿔주게 된다.

확률형태로 변형되면서 0~1사이를 절대 벗어나지 않는다.
암튼 이런 형식때문에 로지스틱 회귀 분석을 공부할 때마다 시그모이드, odd라는 값이 계속 나온다..
위에서는 하지 않았지만,
1, 0 사이에 구체적인 수치들을 얻으려면 predic()함수 대신에 predict_proba()를 통해서 좀더 디테일한 값을 구할 수도 있다.
(추후에 책을 통해 공부하는게 어느정도 잡혀지면, 스스로 하나하나 글을 써봐야겠음...)
'Machine Learning > ML - 데싸노트' 카테고리의 다른 글
| [데싸노트] 선형 회귀 - 보험료 예측하기 (2) | 2022.11.10 |
|---|---|
| [데싸노트] Top 10 알고리즘 (0) | 2022.11.07 |