

코로나 걸리고 정신 못차리고 한두주 가니까 봄이다.
정신차리고 다시 해야지..
이전 포스트에도 몇번 언급을 했었지만, 데이터 분석에 있어서 약간 사기?같은 느낌을 주는 게 부트스트랩이다.
통계량이나 모델 파라미터(모수)의 표본분포를 추정하는 쉽고 효과적인 방법은?
바로 지금 현재 사용하는 표본에서 추가적으로 표본을 복원추출하고 각 표본에 대한 통계량과 모델을 다시 계산하는 방법이다.
이러한 절차를 부트스트랩(Bootstrap)이라고 부른다.
그리고 좀 다른점은 데이터나 표본 통계량이 꼭 정규분포를 따라야 한다는 가정은 필요하지 않다!!!
그니까 다시 개념을 정리해보면
부트스트랩은 원래 표본을 상당히 많은 수, 수백만번정도 복제하는 거라고 생각하면 되는거고, 그 결과를 통해 원래 표본으로부터 얻어지는 모든 정보를 포함하는 가상 모집단을 얻는 것이다.
이 모집단을 그러면 표본분포를 추정할 목적으로 표본을 수집 할 수 있게 된다.
용어를 잠깐 집고 넘어가자면,
- 부트스트랩 표본 (Bootstrap Sample): 관측 데이터 집합으로부터 얻은 복원추출 표본
- 재표본추출(Resampling): 관측 데이터로부터 반복해서 표본추출하는 과정. 부트스트랩과 순서(셔플링)과정이 포함됨
초반에 말한 것 처럼 부트스트랩은 과정이고, 재표본추출이 부트스트랩 과정이 포함된 하나의 definition?이라고 보면 좋을 것같다.
구선생을 통해서 이해하기 쉬운 이미지를 좀 찾아봤는데, 아래의 이미지가 가장 설명을 잘 해주는 듯 하다.
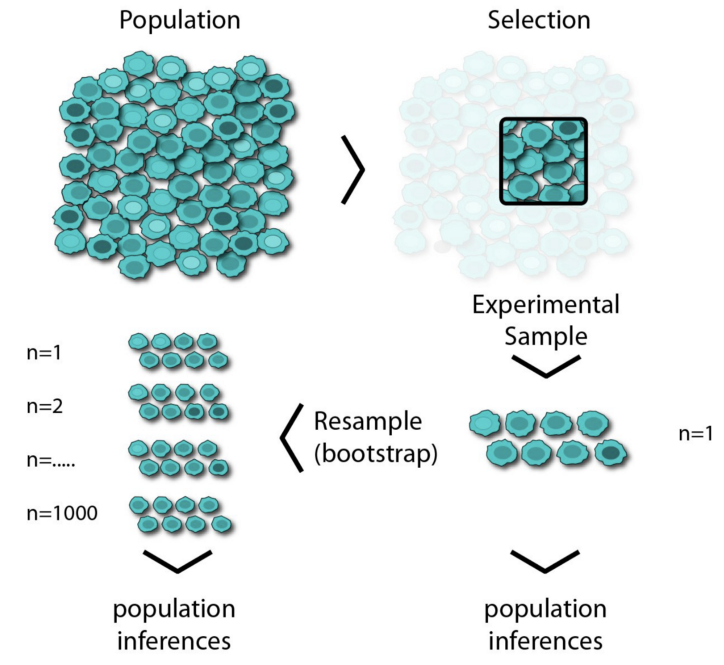
그렇다면, 표본을 실제로 미친듯이 복제를 하냐? 그건 아니다.
대신 각 표본을 뽑은 후에 각 관측치를 원래 자리로 돌려 놓는다 => 복원추출
이런 식의 효과적인 방법으로, 뽑을 때 마다 각 원소가 뽑힐 확률은 그대로 유지하면서 무한한 크기의 모집단을 만들어낼 수 있는 것이다.
저 이미지 처럼, 크기 n 의 샘플의 평균을 구하는 부트스트랩 재표본추출 알고리즘을 보면,
- 샘플값을 하나 뽑고 기록 후에 다시 제자리에 돌려놓는다.
- n번 반복
- 재표본추출된 값의 평균 기록
- 1~3단계를 R번 반복
- R개의 결과를 사용해서,,,
- 표준편차를 구하고
- 히스토그램 또는 상자그림 그리고
- 신뢰구간까지 찾는다.
R(부트스트랩 반복 횟수)번 반복을 할때는 임의로 설정 하지만 횟수가 많을 수록 표준오차나 신뢰구간에 대한 추정이 더 높아진다.
그래서 장점을 딱 정의해보자면,,
부트스랩을 사용하면 통계적 추론?을 위해서 수학공식을 사용하지 않아도 된다는 장점이 있고, 신뢰구간과 머신러닝에도 많이 쓰인다고 보면 된다.
(이번에 회사에서의 목표를 BQML(Bigquery ML)최대한 활용하는건데 잘 참고해서 사용해봐야겠드아..)
코드 예제를 하려고 했는데,
파이썬에서 부트스트랩을 구현하려면, scikit-learn의 resample 방식을 사용해야한다.
어려운건 아닌것같은데, 조금 더 예제 파악하고 좋은 예제를 가지고 해보고싶어서..
사실 회사에서 만지는 트래픽 데이터를 가지고 부트스트랩을 적용하면 딱 좋을 것 같다.
코드는 한번 나눠서 다음 포스트에서 설명하겠다.
'Machine Learning > Practical Statistics' 카테고리의 다른 글
| [Practical Statistics] 정규분포 (0) | 2022.06.04 |
|---|---|
| [Practical Statistics] 신뢰구간 (0) | 2022.05.05 |
| [Practical Statistics] 통계학에서의 표본분포 (0) | 2022.03.26 |
| [Practical Statistics] 선택 편향 (0) | 2022.03.24 |
| [Practical Statistics] 데이터와 표본분포 (0) | 2022.03.20 |