

닥스 대환장 멀티버스 개봉날 바로 보고왔다.
그리고 다음주 IMAX로 예매해놨따. 또 보러갈거다.
(제발 완다비젼만이라도 보고가세요!!!)
'스파이더맨 집에 못 가' 만큼 큼 감동은 아닌데 참 잘만들었어, 굳굳!!!!
앞에서 정리했던 도수분포표나, 히스토그램, 박스플롯 등 모두 표본추정에서 잠재적인 오차를 이해하는 방법이였다.
오늘 공부해 볼 신뢰구간은 위와 다른 방식이다.
쉽게 말해서, 단일화된 수치를 말해주는 것이 아닌 어떤 범위로 추정치를 제시하는 것이 편향되고 불확실성을 인지하는 것을 막는 방법이다.
가장 중요한 것은 신뢰구간은 항상 통계적 샘플링 원칙에 근거한다.
통계공부하다보면 보통 90%, 95%같은 높은 백분율로 표현되는 포함수준으로 나온다.
즉 90%, 95%의 신뢰구간은 표본통계량의 표본분포 90%를 포함하는 구간을 말해준다.
(통계학에서는 더 자세하게 포아송이니 p value니 뭐라뭐라 더 복잡하게 들어가겠지만, 역시 이 책은 딥하게 들어가지는 않는다.)
그럼 신뢰구간을 구하는 방법은 어떻게 되는가??
if 표본크기 n과 관심있는 표본 통계량이 주어졌다고 한다면,,,
- 데이터에서ㅇ 복원추출 방식으로 n인 표본을 추출(재표본추출)
- 재표본추출한 표본에 대해서 원하는 통계량 기록
- 1~2단계를 R번 반복
- x% 신뢰구간을 구하기위해서, R개의 재표본 결과의 분포 양 끝에서 [(100-x)/2]%만큼 잘라낸다
- 절단한 점들은 x%부트스트랩 신뢰구간의 양 끝점이다
뭔가 복잡하게 쓰여져 있는데, 수식과 함께 보면 심플하게 잘 정리해놨다고 보인다.
웃긴게 ㅋㅋㅋ 여기 책에서
'반세기 넘도록 컴퓨터가 없던 시절 통계 교과서 및 소프트웨어에서는 수식, 특히 t분포로 구한 신뢰구간을 사용했다.'
라고 나오는데,,,
손으로 풀고 수식을 이해하면서 풀면 조금이라도 이해가 높아서, 컴퓨터 활용해서 하는 방식을 늦게 배운 나로써는 조큼 아쉬우면서도 자랑스럽?다 ㅋㅋ
(속마음: 졸업 직전까지 나는 손으로 t분포를 통해서 신뢰구간을 계산하고 했었다!! 왜!! 손으로 풀어야 더 이해가 잘되고 아? 원리를 알지?! 아? 코드 짜면 다 모든게 쉬워보이냐? ... 나두 파이썬 빨리 배워보고싶었다고... )
코드 예제
암튼,, Practical Statistics git에 들어가보니까, 신뢰구간 구하는 코드가 있는데, 배워보고싶어서 코드 예제를 가지고 왔다.
(손으로 풀던 시절이 그립다...)
from sklearn.utils import resample먼저 기본적인 import는 다 해주고,
위 순서에서 이야기했던 것 처럼 재표본추출이 필요하기 때문에 sklearn에서의 resample를 가지고오자.
데이터는 대출 신청자의 평균 90%신뢰구간을 구하는 것을 목적으로한다.
그럼 순서처럼, 표본을 몇개 할지 정해주고 통계량을 봐보자.
#그냥 평균을 구하는거
print("그냥 평균값:",loans_income.mean())
#재표본추출을 통해서 평균을 구하는것
#몇번할건지 정해주고
np.random.seed(seed=3)
# 20개의 랜덤 샘플을 통해서 평균 구하기
sample20 = resample(loans_income, n_samples=20, replace=False)
print("재표본추출 이후의 평균값:",sample20.mean())이렇게 되면 위에서의 순서 1, 2를 마무리 한것이다.
그럼 3번째인 R번 반복을 실행해야한다.
반복은 뭐다? for 문이다.
(그리고 이거 예제 코드 보면서 감탄했다..)
#1~2과정을 500변 반복으로 지정
results = []
for nrepeat in range(500):
sample = resample(sample20)
results.append(sample.mean())
results = pd.Series(results)
confidence_interval = list(results.quantile([0.05, 0.95])) #여기서 신뢰구간을 90%구간으로 설정을 해주었고, .95-.05
ax = results.plot.hist(bins=30, figsize=(12, 8)) #히스토그램으로 30개의 bar와, 사이즈 설정해주고
ax.plot(confidence_interval, [55, 55], color='black') # 그려주기
## 90%구간에 수직인 선을 그려주고 표시해주기
for x in confidence_interval:
ax.plot([x, x], [0, 65], color='black')
ax.text(x, 70, f'{x:.0f}',
horizontalalignment='center', verticalalignment='center')
#중간 수평선 통해서 90%구간이라고 텍스트 써주기
ax.text(sum(confidence_interval) / 2, 60, '90% interval',
horizontalalignment='center', verticalalignment='center')
#결과값을 점선을 통해서 지정해주기
meanIncome = results.mean()
ax.plot([meanIncome, meanIncome], [0, 50], color='black', linestyle='--')
#결과값(mean)값을 음영처리해서 가운데에 표시해주기
ax.text(meanIncome, 10, f'Mean: {meanIncome:.0f}',
bbox=dict(facecolor='white', edgecolor='white', alpha=0.5),
horizontalalignment='center', verticalalignment='center')
ax.set_ylim(0, 80)
ax.set_ylabel('Counts')
#마무리 그리기
plt.tight_layout()
plt.show()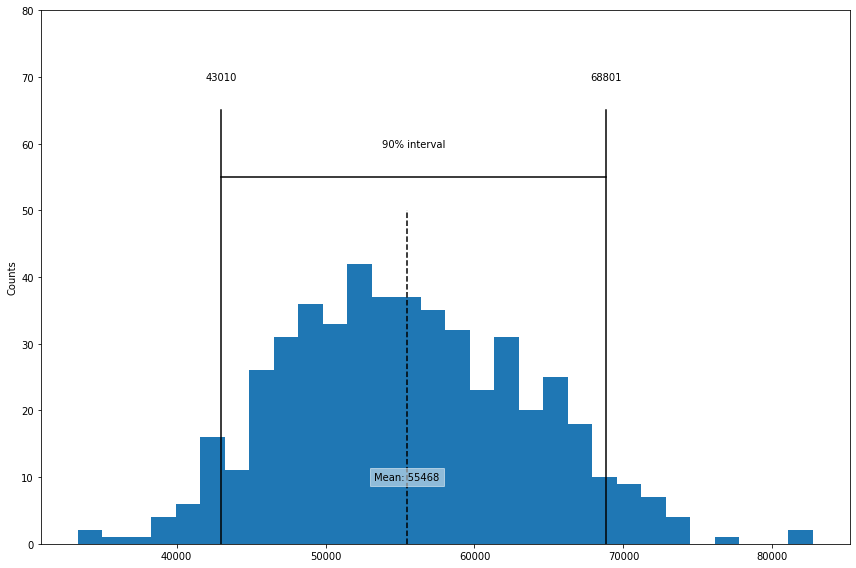
이런거 보면 진짜 손으로 푸는거 참... 회의감 든다니까 이런거 보면..
암튼 너무나 이쁘고 깔쌈하게 그래프가 완성되었다.
중간중간에 선을 그려주면서 90%구간까지 정리해주고 가운데 mean값도 잘 가지고 와줬다.
위에서 보이는 것 처럼 신뢰구간과 관련된 백분율을 신뢰수준이라고 부르기도 한다.
즉 신뢰수준이 높을 수록 구간은 점점 넓어지고, 표본이 작을 수록 넓어지기도 하지만 불확실성이 커진다.
마지막으로 개념을 정리하고 넘어가자면
- 신뢰구간은 구간범위로 추정값을 표시하는 일반적인 방법
- 더 많은 데이터를 보유할수록 표본추정치 변이가 줄어듦
- 허용하는 신뢰수준이 낮을수록 신뢰구간은 좁아진다
- 부트스트랩은 신뢰구간을 구성하는 효과적인 방법!
'Machine Learning > Practical Statistics' 카테고리의 다른 글
| [Practical Statistics] 긴 꼬리 분포 (0) | 2022.06.06 |
|---|---|
| [Practical Statistics] 정규분포 (0) | 2022.06.04 |
| [Practical Statistics] 부트스트랩 (0) | 2022.04.09 |
| [Practical Statistics] 통계학에서의 표본분포 (0) | 2022.03.26 |
| [Practical Statistics] 선택 편향 (0) | 2022.03.24 |