

임시 저장 안하고 썼는데 다 날렸다ㅜㅜ
조금 쉬고, 두번 공부한다고 치고... 다시 쓰자ㅠ
후....!
표본분포는 하나의 동일한 모집단에서 얻은 여러 샘플에 대한 표본 통계량의 분포를 나타냅니다.
뭐 고전 통계라고 책에서 말하지만, 대부분 작은 샘플(표본)을 가지고 모집단을 추론하는 것과 관련이 있다.
이번에는 용어를 한번 정리하고 시작해야 편하다.
- 표본통계량 (Sample Statistics) : 더 큰 모집단에서 추출된 표본 데이터들로 부터 얻은 측정 지표
- 데이터 분포 (Data Distribution): 어던 데이터 집합에서 각 개별 값의 도수 분포
- 표본분포 (Sampling Distribution): 여러 표본들 혹은 재표본들로부터 얻은 표본 통계량의 도수분포
- 중심극한정리 (Central Limit Theorem): 표본 크기가 커질수록 표본분포가 정규분포를 따르는 경향
- 표준오차 (Standard Error): 여러 표본들로 부터 얻은 표본통계량의 변량 (개별 데이터 값들의 변량을 뜻하는 표준 편차와 혼동하면 안된다)
그리고 표본을 추출할때마다 결과가 다를 수 있기 때문에 표본에 따라 결과가 얼마나 달라질지 알아야 하고, 그걸 표본의 변동성이라고 부른다.
여러 말이 책에 있는데, 중요한 말만 좀 정리해보자면
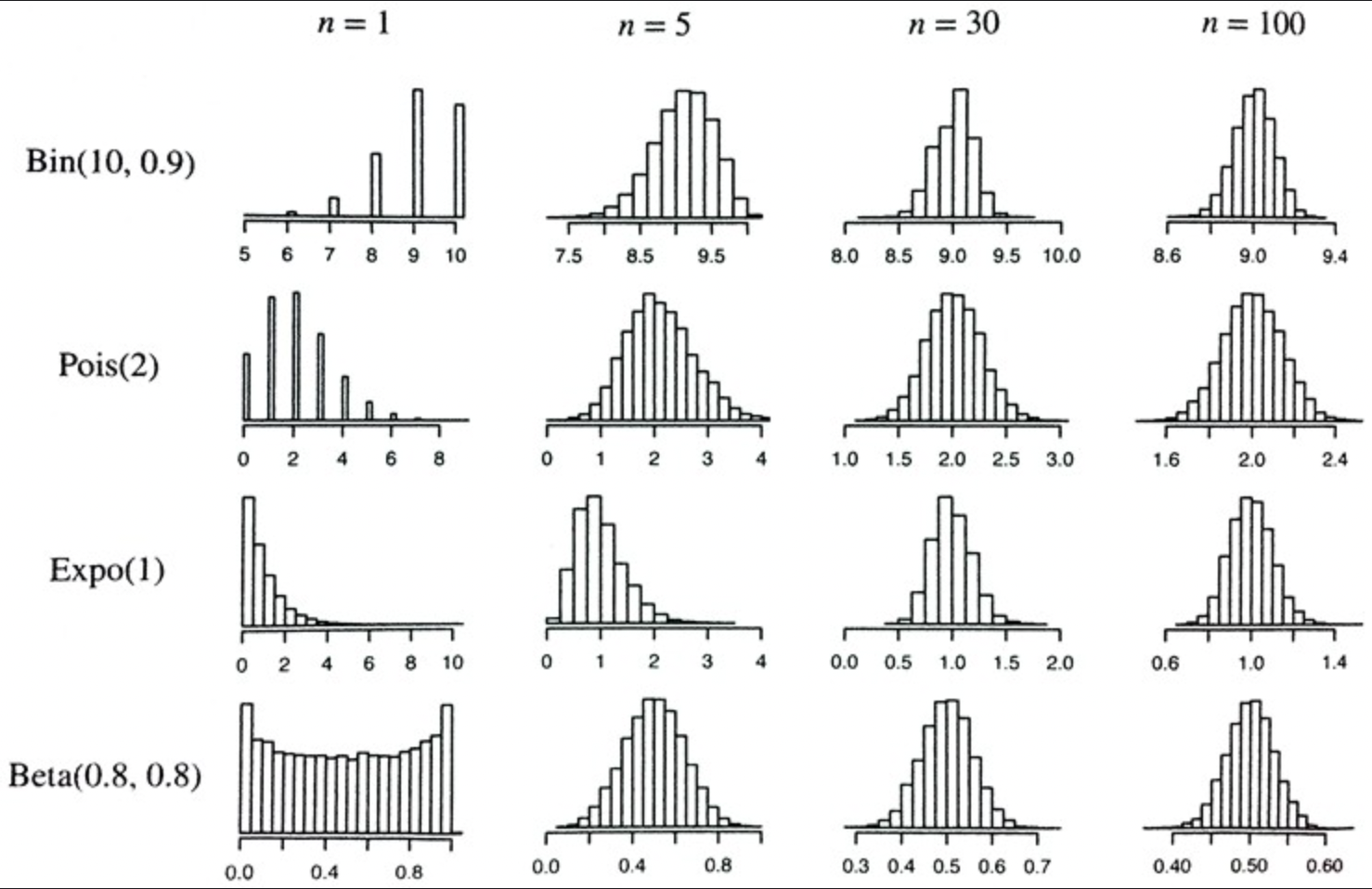
평균과 같은 표본 통계량의 분포는 데이터 자체의 분포보다 규칙적이고 종 모양일 가능성이 높다.
그리고 통계의 기반이 되는 표본이 클수록, 그럴 가능성이 높다는 것이다.
예제와 함께 보면 좀 이해가 편한데,
이번 예제는 렌딩 클럽에 대출을 신청한 사람들을 평가하기 위해 연간 소득 정보 데이터를 가지고 온다.
참고로 이번에 데이터를 가지고 올 때 pd.read_csv 뒤에 squeeze=True를 써주었는데.
squeeze를 잠시 알아보고 가보쟈.
squeeze메서드는 차원을 축소(압축)하는 메서드라고한다.
이번에 가지고오는 데이터 처럼, 한개의 행이나 열만 있는 DataFrame을 squeeze하면 Series(연속성을 가지는) 객체가 되고,
1개 인덱스만 있는 Series를 squeeze하면 스칼라값이 된다.
이번에 True를 써주면서 연속성을 가지게 해야, 히스토그램을 편히 그릴 수 있기 때문에!
암튼 예제 코드와 함께 보면 이해가 쉽다.
(하 아까 다 정리했는데...)
예제 코드
# 단순히 1000개 값으로 이루어진 표본
sample_data = pd.DataFrame({
'income': loans_income.sample(1000),
'type': 'Data',
})
# 5개의 평균 1000개로 이루어진 표본
sample_mean_05 = pd.DataFrame({
'income': [loans_income.sample(5).mean() for _ in range(1000)],
'type': 'Mean of 5',
})
# 20개의 평균 1000개로 이루어진 표본
sample_mean_20 = pd.DataFrame({
'income': [loans_income.sample(20).mean() for _ in range(1000)],
'type': 'Mean of 20',
})
# 세가지의 표본을 하나로 묶어준다.
results = pd.concat([sample_data, sample_mean_05, sample_mean_20])위의 코드처럼 새가지의 표본을 가지구 왔다.
그냥 랜덤 1000개와, 5개의 평균으로 1000, 그리고 20개의 평균으로 1000개를 가지고 와서 비교를 해본다.
쉽게 히스토그램으로 그려주면 편히 보일것이다.
# 아까 위에서 가지고온걸 한번 더 써준것
results = pd.concat([sample_data, sample_mean_05, sample_mean_20])
# 히스토그램을 여러개 표현하기 위해 seaborn에서 FaceGrid를 사용한다.
g= sns.FacetGrid(results, col='type', col_wrap=1, height=2, aspect=2)
g.map(plt.hist, 'income', range=[0,200000], bins=40)
g.set_axis_labels('Income', 'Count')
g.set_titles('{col_name}')
위처럼 개별적으로 가지고 온건 넓게 분산되어있고, 평균으로 가지고 온 히스토그램은 점점 종모양으로 바뀐다.
중심극한정리 (Central Limit Theorem)
위에서 정리한게 중심극한정리이다.
모집단이 정규 분포가 아니더라도, 표본 크기가 충분하고 데이터가 정규성을 크게 이탈하지 않는 경우, 여러 표본에서 추출한 평균은 정규 모양의 정규곡선을 따라가게 되어있다. = 중심극한정리.
아까도 썻지만,, 꼭 아래의 위키를 참고하길 바란다.
생각보다 더 간단하게 써있고 저 움짤을 보면 이해가 더 쉽게 갈 것이다.
중심 극한 정리 - 위키백과, 우리 모두의 백과사전
매우 불규칙한 분포도 충분히 많은 수를 더하면 중심극한정리에 따라 결국 정규분포로 수렴한다. 주사위를 n개 흔들 때 나오는 눈의 합 S n = X 1 + ... + X n의 분포가 n이 확대됨에 따라 정규 분포에
ko.wikipedia.org
물론 학부때 수학적으로 한참 공부하고 손으로 풀었던 것이지만,
해당 책에서는 데이터 과학 관점에서는 부트스트랩을 사용하기 때문에 크게 신경을 쓰지 않는다고 한다. (참고로 부트스트랩은 다음 챕터니까 다음 포스트에 정리할거다.)
표준오차 (Standard Error)
표준오차의 경우 통계에 대한 표본분포의 변동성을 한마디로 말해주는 단일 측정 지표이다.
수식으로도 간단하게 정리가 가능한데, 표준오차는 표본 값들의 표준편차 s와 표본크기 n을 기반으로 한 통계량을 이용해서 추정이 가능하다.
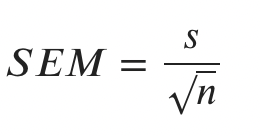
수식에서 보는 것 처럼, 표준오차를 2배로 줄이려면 표본 크기를 4배 시켜야 한다.
표준오차를 고려할때 3가지를 요약해주었는데,
1. 모집단에서 완전히 새로운 샘플을 많이 수집한다.
2. 각각 새 샘플에 대해 통계량을 계산한다
3. 2단계에서 얻은 통계량의 표준 편차를 계산하고, 이것을 표준 오차의 추정치로 사용한다.
실질적으로 표준 오차를 추정하기 위해서 새로운 샘플을 수집하는게 쉽지가 않다.
그래서 대신 부트스트랩 재표본을 사용 할 수 있다고 한다.
현대 통계에서는 부트스트랩은 표준오차를 추정하는 표준 방법이 되었다고도 설명을 해준다.
좀 더 개념을 정리하자면,,,
표본 통계량의 도수분포는 그 해당 지표가 표본마다 다를 수 있다는 것과
부트스트랩방식으로 표본분포를 추정할 수 있고,
표준 오차는 표본 통계량의 변동성을 요약하는 지표라고 말할 수 있다.
(아까보다 더 짧아지긴 했는데, 에너지가 다 떨어졌다..)
'Machine Learning > Practical Statistics' 카테고리의 다른 글
| [Practical Statistics] 신뢰구간 (0) | 2022.05.05 |
|---|---|
| [Practical Statistics] 부트스트랩 (0) | 2022.04.09 |
| [Practical Statistics] 선택 편향 (0) | 2022.03.24 |
| [Practical Statistics] 데이터와 표본분포 (0) | 2022.03.20 |
| [Practical Statistics] 두 개 이상의 변수 탐색하기 (0) | 2022.03.19 |