Intro.

회사일 말고도 다른게 왤케 바쁜지..
회사일은 원래 바뻐, 집안일, 개인일, 다른일, 이것저것일 뭐 뭐 많아 뭐가 이렇게 벌린게 많지?..
이것도 언제 저장한거 마무리하는거냐..
조금 더 길게 휴식이 필요하다요..
아무도 관심 없겠지만, 다시한번 퍼널 분석 정리해보기... 지난번에 했을때랑 약간 헷갈리는부분이 있어서..
1. 서론 (Introduction)
1.1 퍼널분석이란? (What is Funnel Analysis?)
퍼널 분석(Funnel Analysis)은 사용자가 특정 목표(예: 구매 완료)에 도달하는 과정에서 각 단계별로 얼마나 많은 사용자가 이탈하는지를 분석하는 방법론이다.
위키백과의 말을 조금 더 인용해보자면,
퍼널 분석(Funnel Analysis)은 광고에서 구매까지의 여정이나 모바일 앱에서의 사용자 참여에서 판매까지의 흐름과 같이 정의된 목표로 이어지는 일련의 이벤트를 매핑하고 분석하는 과정이라고 하며, 퍼널 분석은 특정 사용자 행동에 대한 전환율을 계산하는 효과적인 방법이라고 소개를한다.
또한 퍼널을 지속적으로 모니터링하고 분석함으로써 애플리케이션이나 플랫폼의 변경 사항이 전환율에 긍정적인 영향을 미치는지 평가할 수 있댜.
즉, 퍼널 분석은 사용자가 어디서 이탈하는지 파악하는 데 도움이 되며, 그 이유를 이해하여 이탈률을 줄이고 전환율을 높일 수 있는 장점이 있다.
하지만 퍼널이 단순한 선형 접근 방식으로만 작동하는 것은 아니다.
현대 소비자들은 더 역동적인 여정을 가지고 있고 (파악하기 불가능), 결정을 내리는 데 다양한 데이터를 더 적극적으로 활용한다고한다.
(by wiki..)
Funnel analysis - Wikipedia
From Wikipedia, the free encyclopedia An example of funnel visualization Funnel analysis involves mapping and analyzing a series of events that lead towards a defined goal, like an advertisement-to-purchase journey in online advertising, or the flow that s
en.wikipedia.org
2. 실습: 퍼널 분석 (Hands-on Example)
2.1 데이터 준비 (Preparing the Data)
데이터는 캐글에서 사용할거다 항상 언제나 그랫듯이.
eCommerce Events History in Cosmetics Shop
This dataset contains 20M users' events from eCommerce website
www.kaggle.com
위 데이터에서 2월꺼로만 일단 테스트하려고 가지고왔다.
2.2. 간단히 전처리
# 결측치 확인해보고
print(data.isnull().sum())
data['category_code'].fillna('Unknown', inplace=True)
data['brand'].fillna('Unknown', inplace=True)
data.dropna(subset=['user_session'], inplace=True)
#날짜 변환때리기
data['event_time'] = pd.to_datetime(data['event_time'])
#데이터 클리닝: 열과 문자열 정리
data.columns = data.columns.str.strip()
data['event_type'] = data['event_type'].str.strip()
data['category_code'] = data['category_code'].str.strip()
data['brand'] = data['brand'].str.strip()
결측치 간단히 처리해버리자.
category_code와 brand 열의 결측치는 "Unknown"으로 채우고, user_session이 없는 행은 삭제.
event_time 열을 datetime 형식으로 변환하여, 시간대별 분석 및 다른 시간 관련 작업을 쉽게 할 수 있도록 준비해보고,
데이터 클리닝의 일환으로, 열 이름과 문자열 데이터에서 불필요한 공백을 제거하여 데이터의 일관성을 유지해보기.
2.3 EDA
import matplotlib.pyplot as plt
import seaborn as sns
# 이벤트 유형 분포
plt.figure(figsize=(10, 6))
sns.countplot(data=data, x='event_type')
plt.title('Event Type Distribution')
plt.xlabel('Event Type')
plt.ylabel('Count')
plt.show()
# 가격 분포
plt.figure(figsize=(10, 6))
sns.histplot(data['price'], bins=50, kde=True)
plt.title('Price Distribution')
plt.xlabel('Price')
plt.ylabel('Frequency')
plt.show()
# 'Unknown'을 제외한 카테고리 분포
plt.figure(figsize=(10, 6))
data_filtered = data[data['category_code'] != 'Unknown']
data_filtered['category_code'].value_counts().head(10).plot(kind='bar')
plt.title('Top 10 Categories (excluding Unknown)')
plt.xlabel('Category')
plt.ylabel('Count')
plt.show()
# 'Unknown'을 제외한 브랜드 분포
plt.figure(figsize=(10, 6))
data_filtered = data[data['brand'] != 'Unknown']
data_filtered['brand'].value_counts().head(10).plot(kind='bar')
plt.title('Top 10 Brands (excluding Unknown)')
plt.xlabel('Brand')
plt.ylabel('Count')
plt.show()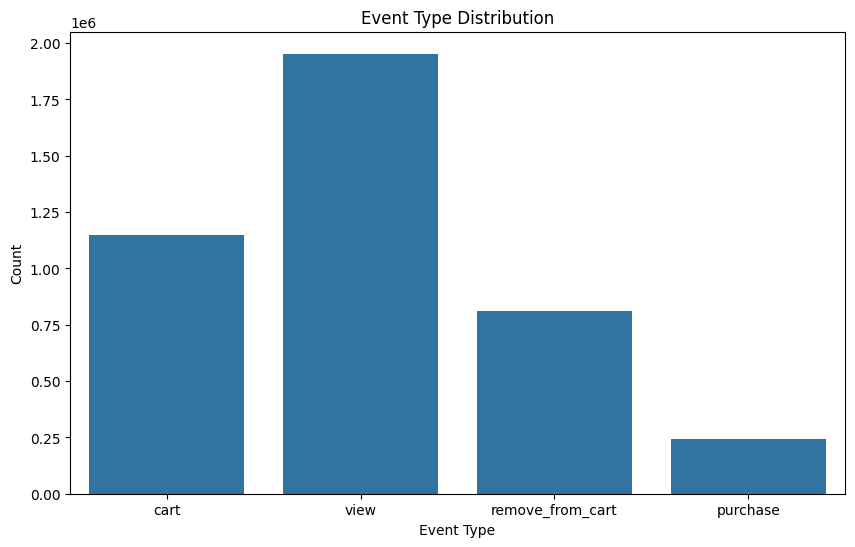
1. 이벤트 유형 분포 차트
아래에서 추가적인 비율을보겠지만 어떤식의 그림인지 어떤식의 분포를 이루고 있는지 간단히 확인했다.
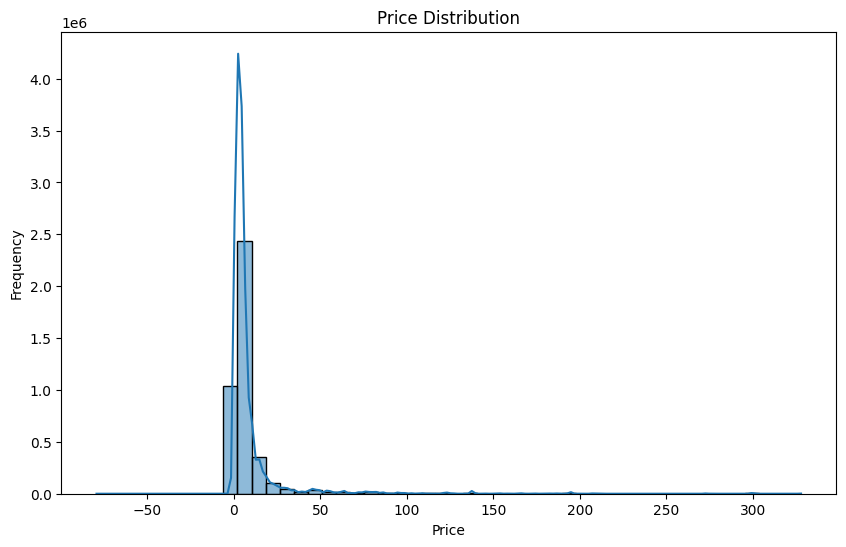
2. 가격 분포 차트
가격 분포는 대다수가 0에 가까운 범위에 몰려 있으며, 일부 상품은 높은 가격대에 속합니다. 즉 엄청 싼 상품이 많은거고..
크게 뭐 가격가지고 할건 없어서 손대지 않겠다.
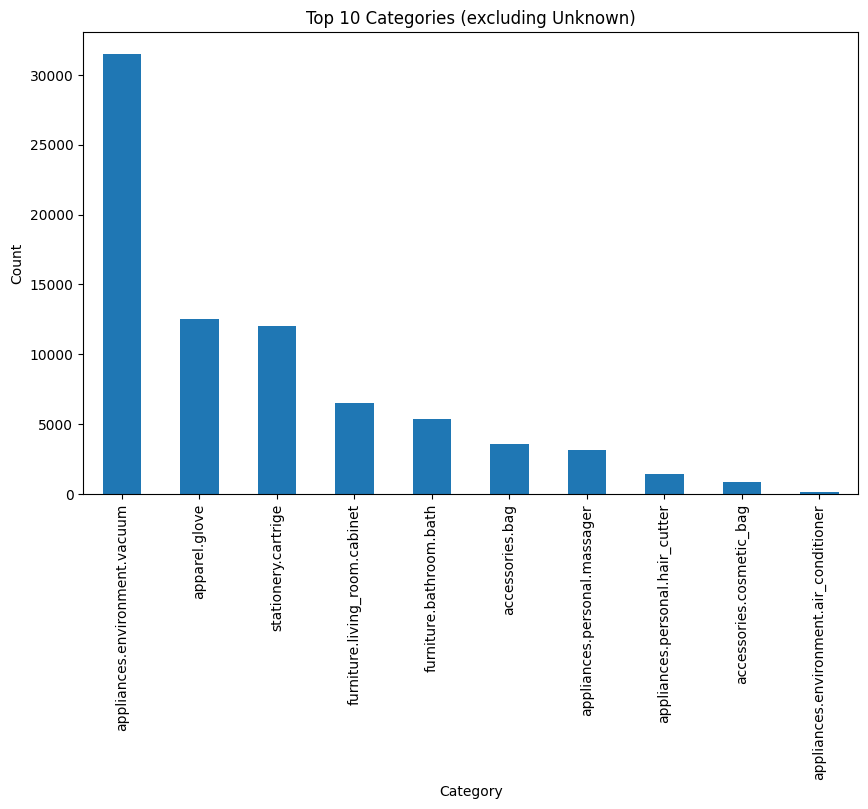
3. 상위 10개 카테고리 분포 차트 ('Unknown' 제외)
'appliances.environment.vacuum' 카테고리가 다른 카테고리보다 현저히 높은 비율을 차지하고 있고, 그 다음으로 'apparel.glove'와 'stationery.cartridge' 카테고리가 높은 비중을 보이는데 뭐가 뭔지 모르겠음... 그냥 청소기 집중인가?
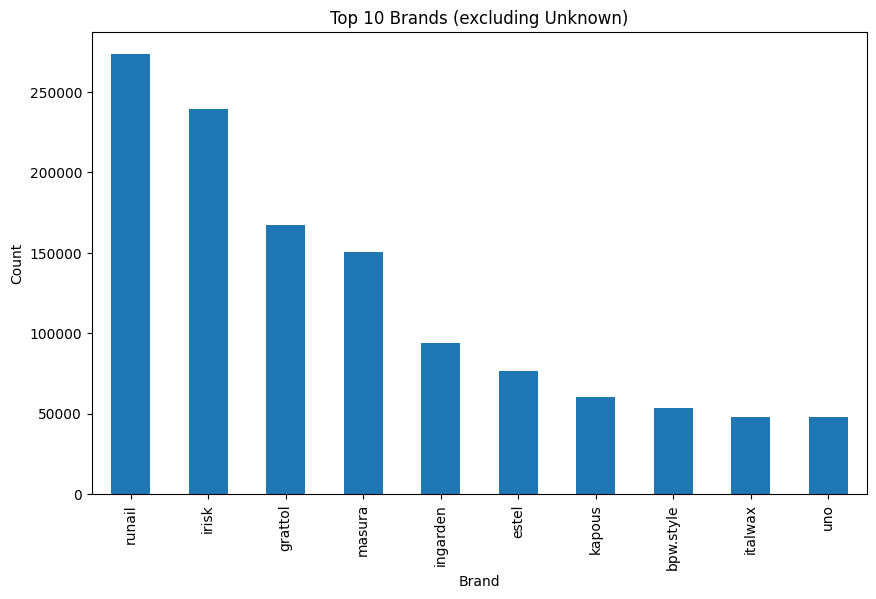
4. 상위 10개 브랜드 분포 차트 ('Unknown' 제외)
'runail' 브랜드가 가장 많은 사용자에게 노출되고 있으며, 'irisk'와 'grattol'이 그 뒤를 이루고있는데 아는 브랜드가 하나도 없당..
2.3 Funnel Analysis
# 이벤트 유형에 따라 단계 정의
event_step = {'view': 1, 'cart': 2, 'purchase': 3}
data['step'] = data['event_type'].map(event_step)
# 각 user_id와 product_id별로 가장 높은 단계(step) 추출
max_step = data.groupby(['user_id', 'product_id'])['step'].max().reset_index()
# 각 단계별 고유 사용자 수 계산
view_users = max_step[max_step['step'] >= 1]['user_id'].nunique()
cart_users = max_step[max_step['step'] >= 2]['user_id'].nunique()
purchase_users = max_step[max_step['step'] >= 3]['user_id'].nunique()
# 각 단계별 전환율 계산
funnel = pd.DataFrame({
'Stage': ['View', 'Cart', 'Purchase'],
'Users': [view_users, cart_users, purchase_users]
})
funnel['Conversion Rate'] = funnel['Users'] / funnel['Users'].shift(1)
# 첫 단계(View)는 전환율을 1로 설정
funnel['Conversion Rate'].iloc[0] = 1
# 전환율을 백분율로 변환
funnel['Conversion Rate'] = funnel['Conversion Rate'] * 100
# 결과 출력
print(funnel)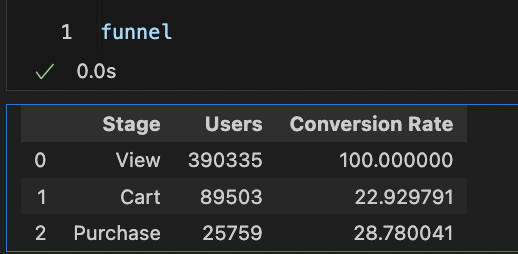
1. 각 단계별 사용자 수 (Users)
- View 단계: 이 단계에서 총 390,335명의 사용자가 있었고 가장 처음 단계다.
- Cart 단계: 89,503명의 사용자가 장바구니에 상품을 추가했는데, 이는 View 단계에서 약 77.1%의 사용자가 이탈했음을 의미
- Purchase 단계: 25,759명의 사용자가 실제로 구매를 완료했고, Cart 단계에서 약 71.2%의 사용자가 이탈했음을 나타낸댜
2. 전환율 (Conversion Rate)
- View에서 Cart로의 전환율: 22.93%의 사용자가 제품을 본 후 장바구니에 추가했습니다. 이는 전체 사용자 중 약 4분의 1이 장바구니에 상품을 추가하고 있음을 의미하고
- Cart에서 Purchase로의 전환율: 장바구니에 추가한 사용자 중 28.78%가 구매를 완료했습니다. 이는 장바구니에 상품을 담은 사용자 중 약 3분의 1이 실제 구매로 이어졌음을 의미한다
그려보자.
# 퍼널 시각화
plt.figure(figsize=(8, 6))
sns.barplot(x='Stage', y='Users', data=funnel)
plt.title('Funnel Analysis: Number of Users at Each Stage')
plt.xlabel('Stage')
plt.ylabel('Number of Users')
plt.show()
# 전환율 시각화
plt.figure(figsize=(8, 6))
sns.lineplot(x='Stage', y='Conversion Rate', data=funnel, marker='o')
plt.title('Funnel Analysis: Conversion Rate at Each Stage')
plt.xlabel('Stage')
plt.ylabel('Conversion Rate (%)')
plt.show()
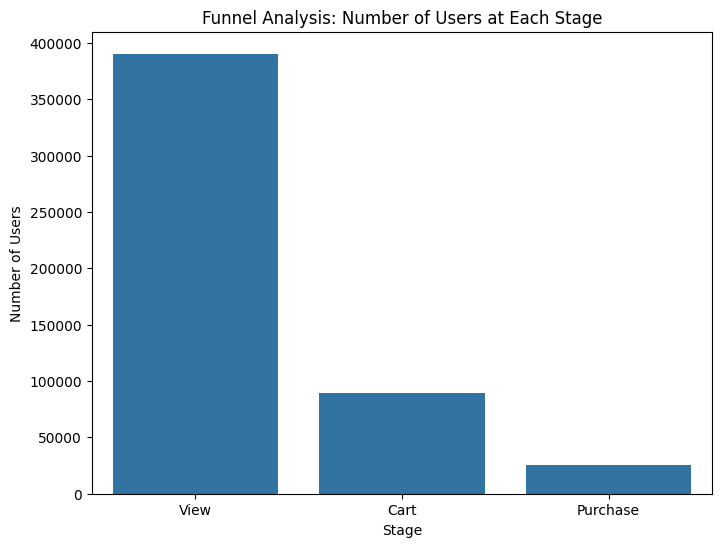
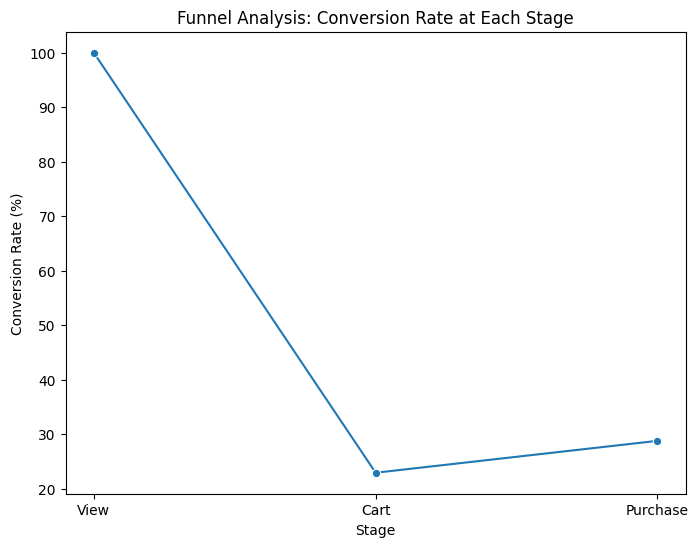
나중에 다른 시각화를 해야겠다.. 귀찮아서 간단하게 해보려다보니까 이쁘진 않지만... 암튼
카트로 전환되는 비율은 확실히 적고 그래도, 카트에서 구매까지 이루어지는 전환율은 조금 더 높은것을 확인할 수 있다.
2.4 Additional Analysis
# 카테고리별 퍼널 분석
category_funnel = data.groupby(['category_code', 'step'])['user_id'].nunique().unstack().fillna(0)
category_funnel.columns = ['View', 'Cart', 'Purchase']
category_funnel['Conversion from View to Cart'] = category_funnel['Cart'] / category_funnel['View'] * 100
category_funnel['Conversion from Cart to Purchase'] = category_funnel['Purchase'] / category_funnel['Cart'] * 100
category_funnel
# 브랜드별 퍼널 분석
brand_funnel = data.groupby(['brand', 'step'])['user_id'].nunique().unstack().fillna(0)
brand_funnel.columns = ['View', 'Cart', 'Purchase']
brand_funnel['Conversion from View to Cart'] = brand_funnel['Cart'] / brand_funnel['View'] * 100
brand_funnel['Conversion from Cart to Purchase'] = brand_funnel['Purchase'] / brand_funnel['Cart'] * 100
brand_funnel
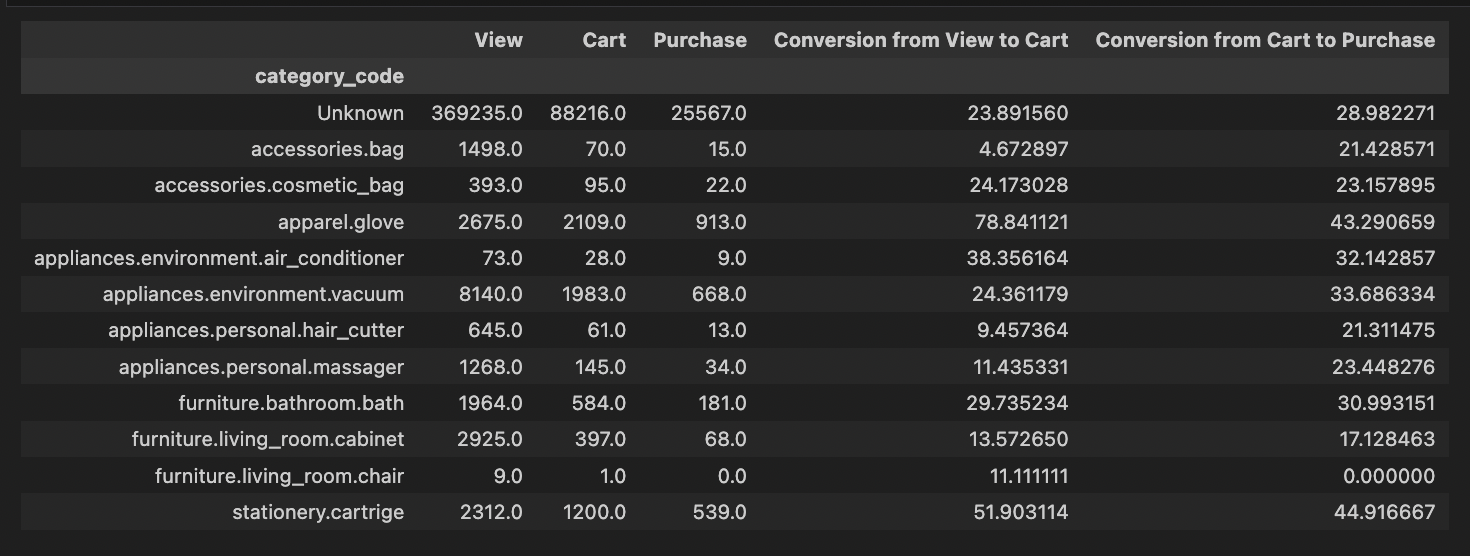
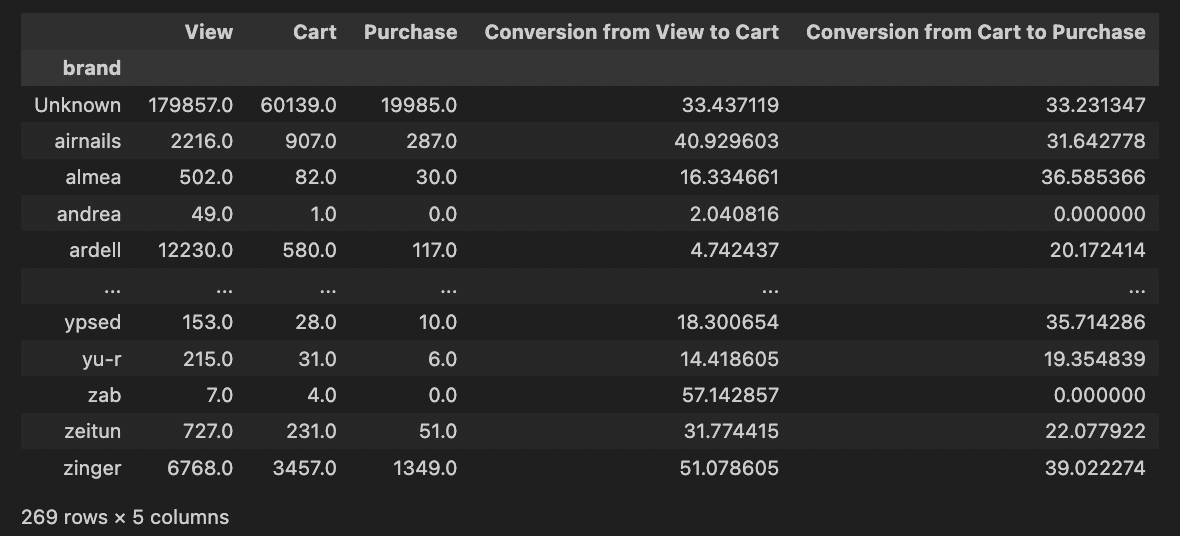
이런식으로 카테고리, 브랜드별로도 퍼널을 분석할수있다.
지금 여기선 대충하지만,, 나중에 업무에서 충분히 활용해볼만하겠다.
시간도 있으니까 한번 쓸쩍
# 시간대별 이벤트 분석
data['hour'] = data['event_time'].dt.hour
hourly_events = data.groupby('hour')['user_id'].nunique()
plt.figure(figsize=(12, 6))
hourly_events.plot(kind='bar')
plt.title('Unique Users by Hour of Day')
plt.xlabel('Hour of Day')
plt.ylabel('Number of Unique Users')
plt.show()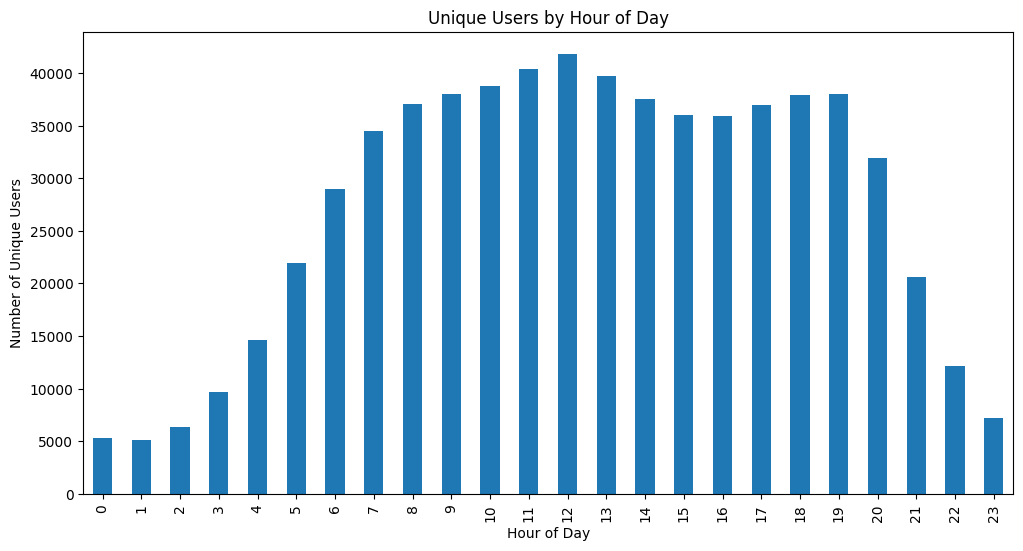
- 옛날에도 이런식으로 시간대별 분석을 한적이 있었는데,
출근시간 점심시간 퇴근 이후시간이 가장 트래픽이 많았다.
이건 진짜 이쁜 그래프인데,
실제 데이터를 또 보면 새벽시간에도 은근히 트래픽(구매, pv, impression 등..)들도 많이 나온적이 있었다.
(자기전에 폰 많이하니깡)
4. 결론 (Conclusion)
퍼널을 했는데 또 하는 이유는 두세번은 해봐야 좀 감이 잡히지 않을까 싶어서였는데, 처음보단는 확실히 여러번 보니까 익숙하고 편해졌다?..
특히, 제품 페이지에서 장바구니로 넘어가는 과정에서 많은 사용자가 이탈한다는 점이 눈에 띄었는데, 뭐 대부분 앱에서 그렇듯이 UX/UI를 개편하거나 다른식으로 전략을 찾아갈것같다.
카테고리나 브랜드별로도 퍼널을 분석해보니, 확실히 어떤 제품군이 더 잘 팔리고 있는지, 어떤 브랜드가 인기가 많은지를 한눈에 알 수 있었는데, 이건 실무에서 꼭 써볼거다. 저 코드로 좀 간편하게...
5. 추가 자료 (Additional Resources)
- https://en.wikipedia.org/wiki/Funnel_analysis
- https://chartio.com/learn/product-analytics/what-is-a-funnel-analysis/
- https://www.kaggle.com/datasets/mkechinov/ecommerce-events-history-in-cosmetics-shop
아오 너무 피곤해..
'Data Analysis > Methodologies' 카테고리의 다른 글
| [데이터 분석 방법론] 감성분석 (Sentiment Analysis) (1) | 2024.08.18 |
|---|---|
| [데이터 분석 면접론?] 데이터 분석가 / 비즈니스 분석가 인터뷰 면접 준비 (0) | 2024.08.15 |
| [데이터 분석 방법론] AARRR 분석 프레임워크 (AARRR) (1) | 2024.07.05 |
| [데이터 분석 방법론] 퍼널 분석 (Funnel Analysis) (2) | 2024.06.23 |
| [데이터 분석 방법론] 코호트 분석 (Cohort Analysis) (0) | 2024.06.16 |